

At IMG.LY, we recognize that leveraging data is essential for driving innovation and growth. To optimize our data for reporting, we consolidate multiple data sources, including Stripe billing and financial data, into Google BigQuery.
IMG.LY is the leading provider of creative editing SDKs for video, photo, and design templates. While this article may not directly relate to media creation, we believe in empowering developers through knowledge sharing. Let’s dive in.
Until now, we’ve relied on Fivetran to fetch our data from Stripe and store it in Google BigQuery. Fivetran uses Stripe’s API, calling each endpoint, iterating over all resources, and storing the results in BigQuery (or any other supported data warehouse). While this generally works well, issues can arise. For instance, we sometimes create Stripe Subscriptions using inline pricing with the price_data parameter. This generates a new Price object in Stripe on-the-fly and immediately sets it to active: false. Consequently, the Price object is not returned by Stripe API’s price endpoint, leading to missing data in our warehouse. Although Fivetran’s support was exceptional in resolving this issue within a day, it highlighted a potential flaw in relying solely on ETL services for data extraction.
Recently, Stripe introduced Data Pipeline, its own service for transferring Stripe data into a data warehouse. This ensures complete, reliable data without needing a third-party service to read Stripe’s API. Additionally, you can receive test environment data and access several tables not available via the API. For a comprehensive summary of the available data, refer to Stripe’s official data schema.
Currently, Stripe supports only Snowflake and Amazon Redshift as data warehouses. However, they’ve recently added the option to deliver data as Parquet files into Google Cloud Storage (GCS). The next step for us was to import this data into Google BigQuery.
Setting Up Stripe Data Pipeline with Google Cloud Storage
Stripe is renowned for its excellent developer experience, and this beta feature is no exception. Enabling it within the Stripe Dashboard is quick, and the documentation is straightforward. After following the instructions and enabling the feature, it takes a while for data to appear in GCS. Once available, a complete data dump is provided every 6 hours, structured as follows:
- At the root level, Stripe creates a folder representing the date and time of the latest transfer, e.g.,
2024071600(YYYYMMDDHH), representing the 12 am push on July 16, 2024. - One level deeper, there are two folders:
livemodeandtestmode, representing live and test data, respectively. - Each folder contains one folder per data table, e.g.,
subscriptionsorinvoices. Additionally, acoreapi_SUCCESSfile indicates successful data transfer to your GCS bucket and readiness for consumption. - Within the table folders are several Parquet files containing the actual data for each table.
Loading the Data from Google Cloud Storage into Google BigQuery
There are multiple ways to transfer data from GCS to BigQuery. We opted for the following approach:
- Using Google Cloud Scheduler to publish a message to Google Pub/Sub every 6 hours at 1 am, 7 am, 1 pm, and 7 pm.
- Creating a Google Cloud Function that listens for new messages on the above Pub/Sub topic. When a message is received, it triggers a Node.js script that loads the most recent data from GCS into BigQuery and deletes it from GCS.
Let’s delve into the details.
Create a Google Cloud Scheduler Job
First, create a new Cloud Scheduler job here with the following configuration:
- Name: Choose a name for this job.
- Region: The region is not crucial for this task; we used
europe-west3since most of our services are in Germany. - Frequency: We want the job to run every 6 hours at 1 am, 7 am, 1 pm, and 7 pm. Stripe publishes data every 6 hours, but it takes time to transfer it to GCS. We chose 1 hour later than Stripe’s push time, so our value is
0 1,7,13,19 * * *. - Timezone: Choose ‘Coordinated Universal Time (UTC)’.
- Target type: Choose ‘Pub/Sub’.
- Select a Cloud Pub/Sub topic: Select or create a new Pub/Sub topic using the default configuration. This is used to trigger the Cloud Function.
- Message body: For this task, we don’t look at the contents of the message, as such the content of this value doesn’t matter. We opted for a simple
loadstring.
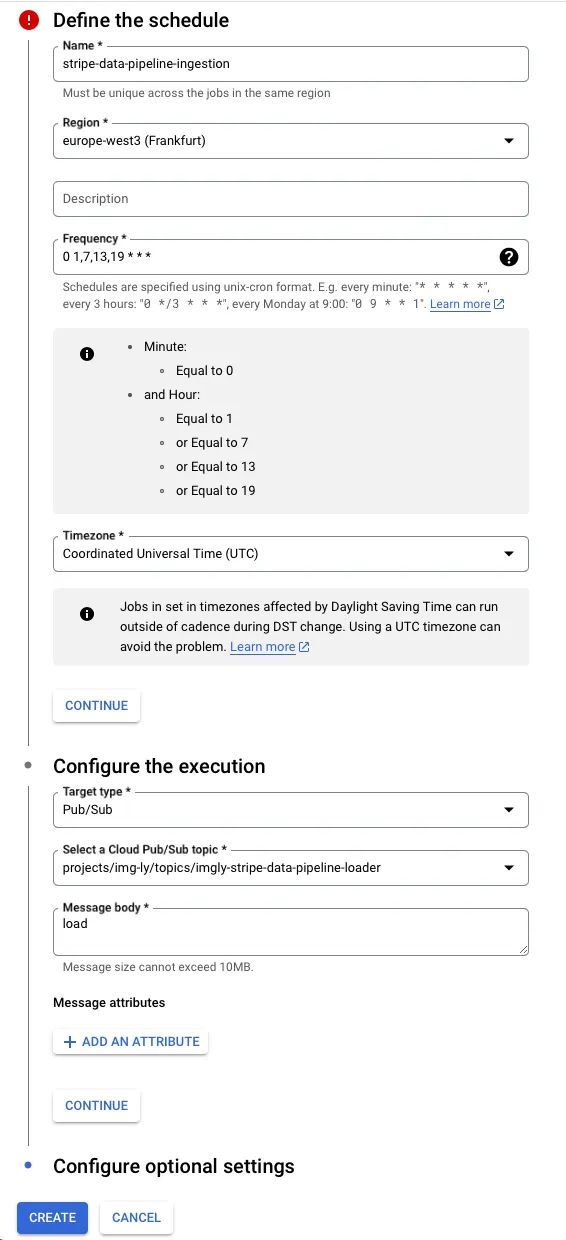
Finally, click ‘Create’ to set up the scheduler. Now, a message is published to the selected Pub/Sub topic every 6 hours. Next, we need to respond to this message.
Create a Google Cloud Function
Create a Google Cloud Function triggered by Pub/Sub here with the following configuration:
- Environment: Choose ‘2nd gen’.
- Function name: Choose a name for this Cloud function.
- Region: Select the region for the function, typically europe-west3 for our services.
- Trigger type: Choose ‘Cloud Pub/Sub’.
- Cloud Pub/Sub topic: Select the Pub/Sub topic created in the previous step.
Adjust the ‘Runtime, build, connections and security settings’ based on your Cloud setup and the required processing power for Stripe data. Generally, the following settings work well:
- Memory allocated: ‘512 MiB’
- CPU: ‘1’
- Timeout: ‘540’
- Minimum number of instances: ‘0’ (to ensure the function shuts down when not in use)
- Maximum number of instances: ‘1’
- Service account: Use or create a service account with permissions to access the GCS bucket where Stripe data is stored and the BigQuery datasets to load the data.
- Ingress settings: Choose ‘Allow internal traffic only’.
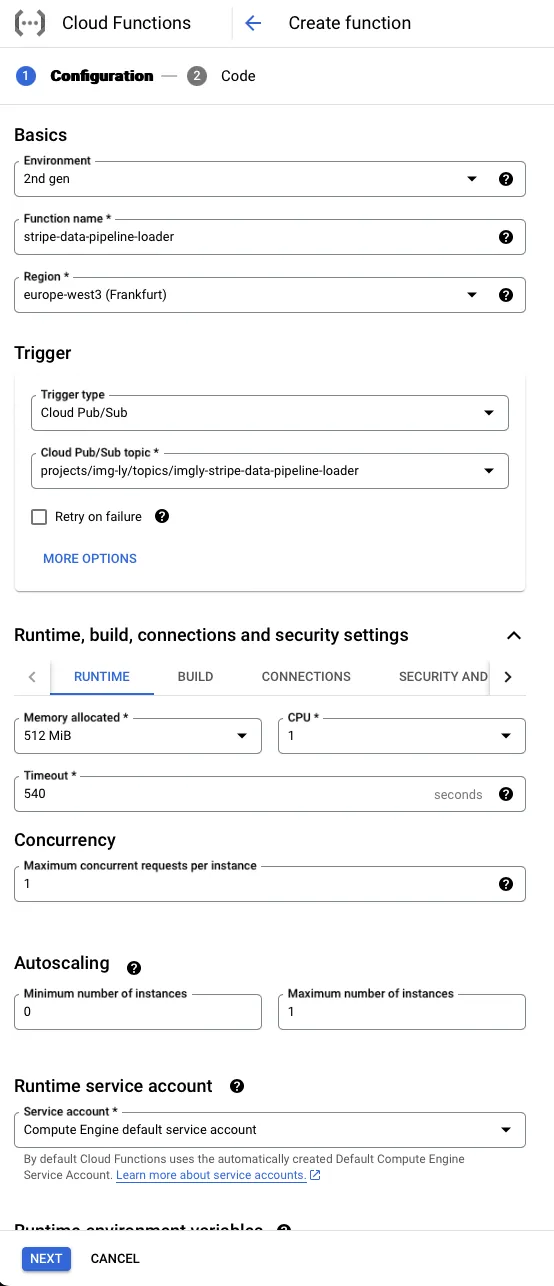
Click ‘Next’ to provide the function’s code. Select:
- Runtime: ‘Node.js 20’
- Source code: ‘Inline Editor’
- Entry point:
loadStripeData
In the package.json, add the BigQuery and Cloud Storage Node.js packages:
In the index.js, add the following code:
This script does the following:
- For each environment (live and test), it searches for the latest folder containing a
coreapi_SUCCESSfile. - For each table, it groups all related Parquet files and loads them into the BigQuery table using
WRITE_TRUNCATE, which overwrites existing data. Note that the location is specified asEU, matching our BigQuery dataset and GCS bucket location. Adjust this parameter if your data is elsewhere. - If all files for an environment are loaded without errors, the files are deleted from GCS. This step is optional; if you prefer to keep a backup, you can omit this part.
Click ‘Deploy’ to deploy your Cloud function.
Create BigQuery Datasets
The final step is to create two datasets in Google BigQuery. Open Google BigQuery, click on the three dots next to your project’s name, and select ‘Create dataset’. Enter a name and choose a location matching your GCS bucket’s location. Repeat this process for the test dataset.
Conclusion
Following these steps will ensure your Stripe data is imported into BigQuery and automatically updated every 6 hours. However, as Data Pipeline for GCS is still in beta, there are some limitations. For example, the schema of the Parquet files lacks type annotations for timestamps, so all timestamps in BigQuery are represented as INTEGER instead of TIMESTAMP.
Additionally, some tables, such as subscription_item_change_events, are not currently transferred when syncing with Google Cloud Storage, although this issue is expected to be resolved soon. Meanwhile, we continue to use Fivetran in conjunction with the above method to sync Stripe data to Google BigQuery and plan to fully migrate to Data Pipeline once it exits the beta phase.
Thank you for reading!
3,000+ creative professionals gain exclusive access and hear of our releases first. Subscribe to our newsletter and never miss out.


