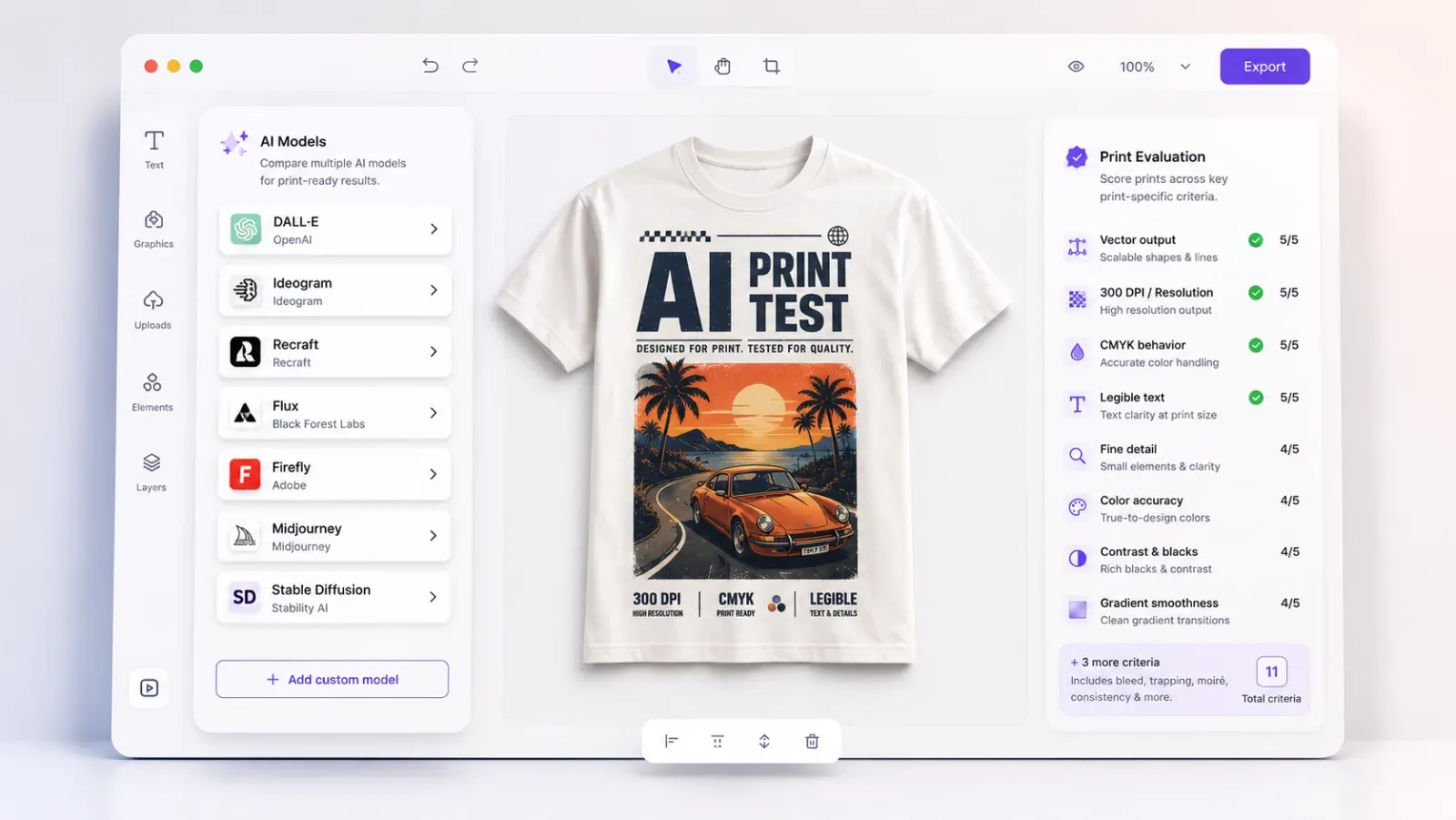
No single generative model is “best” for web-to-print. The right pick depends on the specific job, and print has jobs that screen-first leaderboards don’t measure. A model that tops a general image-quality benchmark can still be useless for print if it can’t render legible text, can’t output vector, or shifts hard out of CMYK gamut.
This guide gives you the criteria that actually matter for print, a scoring rubric to apply them, and a model-by-model read on where each one wins. The goal is to route each task to the model that fits it, which is why a model-agnostic (“bring your own model”) integration matters more than any one provider’s marketing.
How to read this guide. The criteria and rubric are the durable part. The model roster moves monthly: treat the specific model notes as a snapshot, and re-run the rubric against current versions before you commit. The per-model benchmark scores come from IMG.LY’s print benchmark suite, which we’re opening to early-access subscribers soon (sign-up at the end of this guide).
Why print needs its own criteria
A web-to-print product sells a physical object. That changes what “good” means:
- The output is measured at 300 DPI on a substrate, not at 72 PPI on a retina screen.
- Color is CMYK and spot, not sRGB.
- Logos and type must scale and stay crisp: vector, not pixels.
- The customer is a non-designer, so the model has to be controllable enough to stay inside a template.
- And because it’s a commercial product sold to a customer, the licensing of the output carries real legal exposure.
General benchmarks (LMArena-style human preference, aesthetic scores) miss most of this. The eleven criteria below are built around it.
The eleven evaluation criteria
1. Output type and format: raster vs. vector
Why it matters for print: Logos, icons, line art, and type need to scale to any size and print crisply. Raster can’t; vector can. A model that outputs (or can be cleanly traced to) native SVG / vector is uniquely valuable for the print-specific elements that screen apps don’t care about.
What to test: Can it produce vector natively? If not, how cleanly does its output vectorize? Does the vector survive into PDF/X as real paths?
2. Resolution and maximum dimensions
Why it matters: A ~1024px generation is ~3.4” at 300 DPI. Large-format and even A4 need far more. Native max resolution, and how well the model holds detail when upscaled, determines whether you can print the output at size without a quality penalty.
What to test: Native max output dimensions; detail retention at 4×/8× upscale; effective printable size at 300 DPI.
3. Visual quality and fidelity
Why it matters: The baseline. Realism, coherence, absence of artifacts, anatomical and structural correctness. Crucially, how it holds up under print’s unforgiving close inspection: banding, mushy detail, and plasticky textures show more on paper than on screen.
What to test: Side-by-side preference on print-representative prompts; artifact rate; detail at print scale.
4. Text and typography rendering
Why it matters: Print is full of words, and most models garble text inside images. For anything where text-in-image is unavoidable (a generated poster, a label motif), legibility and kerning are make-or-break. Best practice is still to set real type as a separate layer, but some jobs need it baked in.
What to test: Legibility of short and long strings; correct spelling; kerning; multi-line; non-Latin scripts.
5. Prompt adherence and controllability
Why it matters: Non-designers need predictable results, and templates need the output to land where it’s told. Controllability spans prompt adherence, image-to-image / inpainting / outpainting, style and reference-image conditioning, and seed stability for repeatable results.
What to test: Does it honor constraints? Quality of edits (generative fill, expand, object removal)? Reference-image fidelity? Same-seed reproducibility?
6. Color accuracy and CMYK-readiness
Why it matters: Vivid RGB outputs clip hard in CMYK and shift on press. Models that stay closer to printable gamut, and outputs that convert predictably, mean fewer surprises and less soft-proofing friction.
What to test: Gamut coverage vs. CMYK; shift magnitude after ICC conversion; behavior on brand-critical colors and near-whites/blacks.
7. Transparency and background handling
Why it matters: Merch, stickers, die-cuts, and product compositing need clean subjects on transparent backgrounds and accurate edges (hair, glass, fine detail). Native transparent output and clean cutout edges save a manual masking step.
What to test: Native alpha output; edge quality on hard cases; cutout-path readiness.
8. Responsiveness / latency
Why it matters: Two very different bars. In an interactive editor, anything over a few seconds breaks flow. In a batch/VDP run, throughput and concurrency matter more than per-image speed. The right model differs by context.
What to test: P50/P95 latency at your resolution; throughput under concurrency; cold-start behavior.
9. Cost per generation
Why it matters: Unit economics. A few cents per image is invisible for interactive one-offs and brutal across a 100k-recipient VDP run. Price has to be weighed against quality for the specific job. You don’t pay flagship prices for a draft thumbnail.
What to test: Cost per image at your resolution/step settings; cost of edit vs. generate; volume pricing.
10. Consistency and repeatability
Why it matters: Brand work needs the same input to yield the same (or controllably similar) output, and product likenesses must not drift. Seed control, character and style consistency, and low variance separate “brand-safe” models from “slot-machine” ones.
What to test: Variance across runs at fixed seed; character/style consistency across a set; drift on iterative edits.
11. Commercial licensing and IP safety
Why it matters: You’re selling the printed output. Commercial-use rights, training-data provenance, indemnification, and content/safety filtering are legal exposure, not fine print. A model that’s brilliant but legally murky is a non-starter for a product customers resell.
What to test: Commercial-use terms; indemnity; provenance/transparency; enterprise and data-handling terms; content-filter behavior.
The scoring rubric
Score each model 1–5 on each criterion, then weight by your use case. Suggested weights for the three most common web-to-print contexts:
| Criterion | Interactive design tool | High-volume VDP / automation | Merch / POD |
|---|---|---|---|
| 1. Vector / SVG output | High | Medium | Medium |
| 2. Resolution / max size | High | High | High |
| 3. Visual quality | High | Medium | High |
| 4. Text rendering | Medium | High | Medium |
| 5. Controllability / editing | High | High | High |
| 6. CMYK-readiness | High | High | High |
| 7. Transparency / cutout | Medium | Low | High |
| 8. Responsiveness | High | Medium (throughput) | High |
| 9. Cost per generation | Medium | High | Medium |
| 10. Consistency | Medium | High | High |
| 11. Licensing / IP | High | High | High |
Scoring scale: 1 = unusable for print · 2 = weak · 3 = workable with mitigation · 4 = strong · 5 = best-in-class.
Drop your internal benchmark numbers into the matrix below. The qualitative notes give you a starting hypothesis to test, not a substitute for your own runs.
Models by job
New models ship faster than any ranking can keep up with, so this section is organized by job, the way you actually route requests. Models are drawn from the roster currently wired into CE.SDK’s AI plugins.
Job A: Text-to-image (generate a new asset)
Candidates: Recraft V3, Recraft 20B, Seedream V4, Nano Banana, Nano Banana Pro, GPT Image 1, Ideogram V3.
| Model | Stand-out for print | Watch-outs | Benchmark |
|---|---|---|---|
| Recraft V3 | The print specialist: native vector/SVG generation, strong text rendering, brand-style controls. Often the single most print-relevant text-to-image model. | Verify max raster resolution for large-format jobs. | … coming soon |
| Recraft 20B | Faster, cheaper Recraft tier. Good for interactive iteration before a final Recraft V3 render. | Quality step-down vs. V3. | … coming soon |
| Seedream V4 | High visual fidelity and resolution; strong general-purpose hero imagery. | Text rendering and vector are not its strength. | … coming soon |
| Nano Banana / Pro | Fast, controllable, strong prompt adherence; Pro for higher quality. Good interactive default. | Confirm commercial-licensing terms for resale. | … coming soon |
| GPT Image 1 | Strong instruction-following and comparatively reliable in-image text; good for layout-aware generation. | Latency and cost on the higher side for interactive use. | … coming soon |
| Ideogram V3 | Best-in-class text rendering: the pick when legible words in the image are non-negotiable (posters, typographic art). | Less suited to photoreal product scenes. | … coming soon |
Routing heuristic: logos, icons, and typographic art go to Recraft V3 (vector). Words-in-image goes to Ideogram V3 or GPT Image 1. Photoreal hero imagery goes to Seedream V4 or Nano Banana Pro. Fast interactive drafts go to Recraft 20B / Nano Banana.
Job B: Image editing (adapt a customer’s asset)
Candidates: Flux Pro Kontext, Flux Pro Kontext Max, Nano Banana Edit, Nano Banana Pro Edit, Qwen Image Edit, Gemini Flash Edit, Seedream V4 Edit, GPT Image 1, Ideogram V3 Remix.
| Model | Stand-out for print | Watch-outs | Benchmark |
|---|---|---|---|
| Flux Pro Kontext / Max | Strong instruction-based editing with high subject preservation: change one thing without wrecking the rest. Good for generative fill/expand and targeted edits. | Max tier costs more; budget per edit. | … coming soon |
| Nano Banana Edit / Pro Edit | Fast, controllable edits; good interactive default for object removal and swaps. | Verify edge quality on fine detail. | … coming soon |
| Qwen Image Edit | Strong editing with good text handling during edits. | Validate commercial terms. | … coming soon |
| Gemini Flash Edit | Low latency: the responsiveness pick for interactive editing. | Quality trade-off vs. heavier models. | … coming soon |
| Seedream V4 Edit | High-fidelity edits matching its generation quality. | Heavier; weigh latency. | … coming soon |
Routing heuristic: precise “change X, keep everything else” goes to Flux Kontext. Fast interactive edits go to Gemini Flash Edit / Nano Banana Edit. Edits that must preserve in-image text go to Qwen Image Edit.
Job C: Specialized print operations
These aren’t single “models” so much as task pipelines, but they belong in the routing table:
| Task | Approach / model | Note |
|---|---|---|
| Vectorize (raster → SVG) | Vectorize plugin / Recraft vector | The print-critical one: protects logos and PDF/X vector output. |
| Background removal | @imgly/background-removal (in-browser) | On-device, instant, privacy-preserving. Feeds cutout paths. |
| Image correction & DPI | Perfectly Clear plugin + DPI validation | Auto-corrects exposure, color, sharpness, and noise; validation flags undersized images. Prefer high-res native generation over upscaling. |
| Text generation / copy | Claude Sonnet 4.6, GPT-4.1 Nano | Headlines, rewrites, per-recipient VDP copy. |
| Text-to-speech / sound | ElevenLabs (where relevant) | Less common in print; relevant for multi-channel campaigns. |
The quick-reference picks
If you skip the rubric and just want today’s defaults, this is the snapshot we’d start from. Treat it as the hypothesis your own benchmarks confirm or overturn, not a verdict.
| Print job | Pick | Why |
|---|---|---|
| Logos, icons, line art, anything that must scale | Recraft V3 | The only major model with native SVG/vector output. Everything else hands you pixels to trace. Vector survives into PDF/X as real paths and prints sharp at any size. |
| Legible text inside the image (posters, labels, packaging motifs) | Ideogram V3, with GPT Image 1 / Nano Banana Pro close behind | Ideogram was built around typography; kerning and spelling hold where most models produce letter-shaped mush. Still, bake text in only when you must: real type as a separate editor layer beats all of them. |
| Photoreal hero imagery at print size | Seedream V4 or Nano Banana Pro | Resolution is the print bottleneck. Seedream V4 generates up to 4K natively (about 13.6” at 300 DPI before any upscaling); Nano Banana Pro outputs 2K/4K. A 1024px generation from anything else is a 3.4” image betting on the upscaler. |
| ”Change X, keep everything else” edits | Flux Kontext Pro / Max | Best-in-class instruction-following edits with subject preservation, which is critical when the asset is the customer’s product photo and “the AI improved it” means a reprint. The Nano Banana family is the consistency pick for variants of one subject. |
| Interactive drafts (speed and cost) | Recraft 20B, Gemini Flash Edit, base Nano Banana | In an editor, a 20-second generation is a bounce. Draft cheap and fast, then re-render the final with the heavyweight. The customer never needs to know two models were involved. |
| Data sovereignty / self-hosting | Qwen-Image / Qwen Image Edit | Apache 2.0 open weights. For European operators and government buyers who won’t send customer uploads to a US API, “we can run it ourselves” beats a quality delta. |
| VDP copy and headlines | Claude Sonnet 4.6 | Cheap enough per recipient at 100k-mailer volume, and strong at length-constrained rewriting: the “fit this text frame” problem. |
Two of those rationales carry more weight than the rest.
Vector is the criterion that decides printability. Screen products never need vector, so general models never optimized for it, and Recraft sits almost alone on the one measure that determines whether a logo prints cleanly at size. If you adopt a single routing rule from this guide, make it this one.
Resolution and color are pipeline problems the model can only start. No model outputs CMYK; every one generates sRGB. “CMYK-readiness” is really about how hard a model’s palette clips on conversion, and your ICC and soft-proofing pipeline owns the rest. Same with DPI: pair every generation path with validation and a dedicated upscaler rather than trusting native output. You can swap the model whenever you want; the print-correctness layer around it has to stay put.
One roster note: Adobe Firefly isn’t wired into CE.SDK’s plugin roster today, but for licensing-sensitive enterprises its trained-on-licensed-content and indemnification story is the strongest answer to criterion 11. Include it in your own evaluation if criterion 11 dominates your weighting.
A worked decision: which model wins for your product?
The rubric resolves to a different answer per context. Three quick reads:
-
Interactive design tool (non-designers personalizing templates). Weight responsiveness, controllability, and vector. Likely stack: Recraft 20B / Nano Banana for fast generation, Recraft V3 for final vector, Gemini Flash Edit for interactive edits. The customer iterates fast and the final asset is print-clean.
-
High-volume VDP / automation (100k personalized mailers). Weight cost, throughput, consistency, and licensing. Likely stack: a cost-efficient generation model at high concurrency, Claude Sonnet 4.6 for per-recipient copy, seed-locked for repeatability, all run headless. Per-unit cost dominates the decision.
-
Merch / POD (user art on physical products). Weight transparency/cutout, resolution, and quality. Likely stack: background removal plus cutout for subjects, upscaling for resolution, Seedream V4 / Nano Banana Pro for generated designs, with hard licensing checks because the output is resold.
In every case, the conclusion is the same: no one model wins all three. The advantage is in being able to route each task to the model that wins it, and to swap models as better ones appear, without re-architecting your editor.
What makes per-job routing practical: native plugins + the AI Gateway
A criteria-driven, route-per-job strategy only works if switching models is cheap. If wiring in a new model means a new API integration, new auth, new key management, new error handling, and new billing plumbing every time, you’ll quietly standardize on whatever you integrated first, and inherit its weaknesses on every job it loses.
CE.SDK is built to avoid that:
- Every image model in this guide is natively supported as an AI plugin. Text-to-image and image editing run as drop-in providers inside the editor, not bespoke integrations you build and maintain. Background removal, vectorization, and image correction (Perfectly Clear) ship as their own plugins, and text generation routes through built-in Anthropic and OpenAI providers. Adopting Recraft for vector, Ideogram for text, and Flux Kontext for edits is configuration, not three separate engineering projects.
- The AI Gateway gives you one unified surface to every model. Instead of stitching together a dozen provider APIs, key schemes, and rate-limit behaviors, you call models through a single managed layer. That’s what turns “route each task to the best model” from an architecture diagram into a one-line config change, and what lets you swap a model the day a better one ships, without touching your editor or your print pipeline.
- Outputs land inside the print pipeline, not beside it. Whatever model produces the asset, it flows into locked templates with bleed, safe-area, and DPI constraints, then through CMYK / spot-color / PDF/X-3 export. The model is interchangeable; print correctness is not. Print-on-demand company The Print Bar and direct-mail platform PostBuddy both built on this pipeline, embedding CE.SDK rather than maintaining their own print editor.
So the “best model” question is no longer a one-time, high-stakes bet on a single provider; it’s an ongoing optimization. The benchmark scores below tell you which model to route each job to today, and the native-plugin and Gateway architecture is what lets you act on that answer and revisit it when the scores change next quarter.
The IMG.LY print benchmark matrix
IMG.LY is building a print benchmark suite that scores every model in this guide against all eleven criteria, on print-representative prompts, with the weighted totals per use case already worked out. It is rolling out to early-access subscribers first. Subscribe to our newsletter to get the full scored matrix, and the test set behind it, before it is public.
The criteria and the routing logic above stand on their own. The scored numbers are what the suite adds: a measured, repeatable answer for each cell, refreshed as models change.
Bottom line
Pick criteria before you pick models. For web-to-print, the criteria that screen benchmarks ignore (vector output, print resolution, CMYK behavior, text legibility, licensing) are exactly the ones that decide whether a beautiful generation is a sellable print. Score the current models against those criteria for your context, route each job to the model that wins it, and run it all through CE.SDK’s native AI plugins and AI Gateway so re-routing tomorrow, after the next leaderboard reshuffle, is a config change rather than a rebuild.
Companion piece: How to Leverage Generative AI in Web-to-Print covers the use cases, integration patterns, and print-specific pitfalls behind these model choices.