A New Paradigm for Creative AI, Built by IMG.LY
To say it’s trite to refer to the impact of AI in this or that domain as disruptive or groundbreaking would be an understatement. Yet, few areas have been as profoundly affected as the creative process. With just a text prompt, anyone can produce stunning images, remix visual styles, and explore design possibilities at a scale and speed never seen before. AI has inserted itself so quickly into this process that its gone from curious novelty to an essential part of the creator toolchain.
The more serious adoption we see, however, the more key limitations of today’s AI tooling come into focus: the prompt itself.
Text alone, for all its expressive power, struggles to capture the essence of visual intent. Most creative work doesn’t begin with a sentence it begins with a sketch, a layout, a mood board, or an arrangement of elements. Visual ideas are shared by pointing, placing, showing.
At IMG.LY, we have begun to think about better ways to direct AI for visual generation, the term we use is Visual Prompting.
Visual Prompting: the practice of composing a visual scene or layout as input for a generative model.
Instead of describing what you want with paragraphs of text, you show it directly using a canvas of images, text, spatial cues, and annotations. This visual composition then becomes the prompt for the AI to generate new content in return. It’s a more natural, intuitive, and powerful way to collaborate with AI, especially when integrated directly into the creative process.
Problem: the Chat Disconnect
The current generation of AI tools has largely been shaped by language-first interfaces. Whether it’s ChatGPT for writing or Midjourney for image generation, the assumption is the same: the user will type a descriptive prompt, and the AI will generate a result based on it.
But when it comes to design, this workflow quickly runs into friction. Visual ideas are inherently spatial and non-linear. Trying to express layout, balance, mood, or specific spatial relationships through text can feel like trying to describe a painting over the phone. It’s possible but unnecessarily cumbersome.
A designer might want to:
- Indicate that a certain area in the image should be blue.
- Replace a background with a texture sample.
- Position a character precisely in a composition.
- Annotate which parts of a scene to preserve or modify.
All of these are difficult to express fluently in text. But they’re effortless in a visual interface. The truth is: an image is worth more than a thousand words when prompting an image.
What Is Visual Prompting?
Visual Prompting is a multimodal approach to generative AI, where the input to the model is not just text, but a full visual composition: images, text, annotations, and layout.
Rather than prompting AI in isolation, the user builds their intent on a canvas. This might include:
- Reference images that communicate mood or style.
- Text blocks indicating desired copy or instructions.
- Annotations pointing to specific areas with notes like “make this glow” or “replace this object.”
- Spatial composition: where elements are arranged meaningfully to convey intent.
The visual prompt is then interpreted by a multimodal model such as OpenAI’s gpt-image-1 to generate new visual content that reflects not only the textual description, but also the visual context.
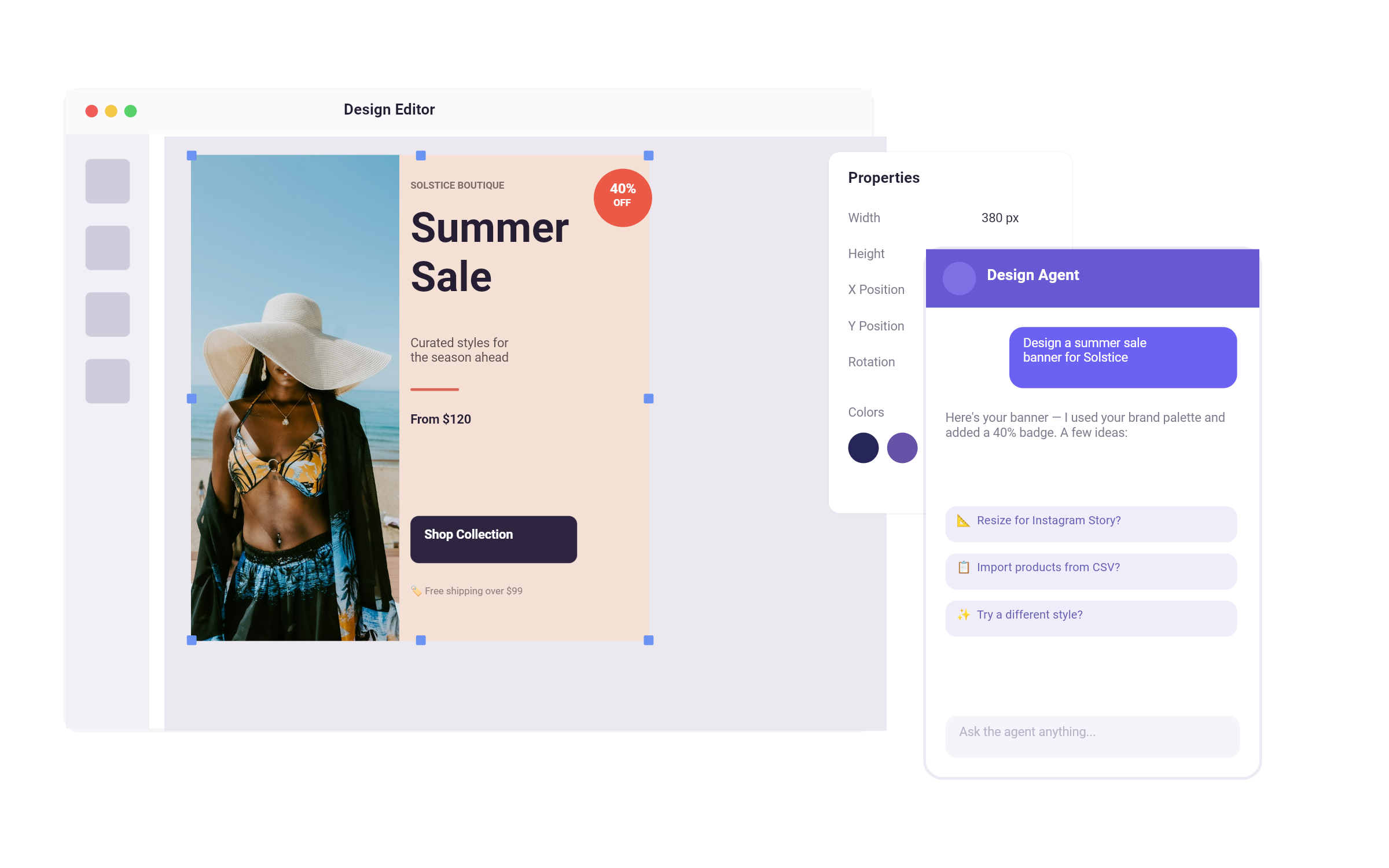
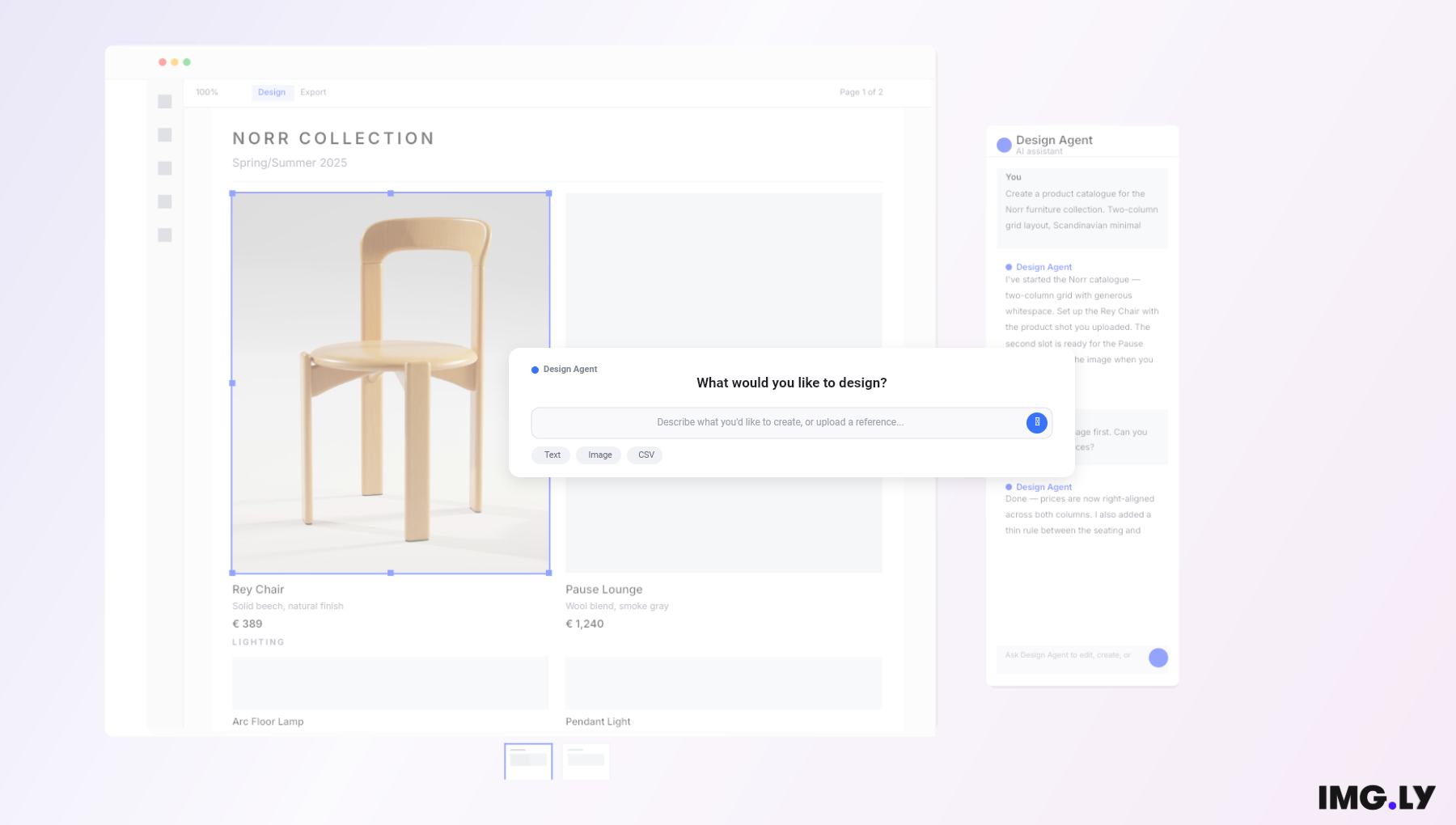
How Visual Prompting Works in CE.SDK
About time for an example. As part of our recent AI released we demoed how to use OpenAIs gpt-image-1 model to build visual prompting into CreativeEditor SDK (CE.SDK).
Here’s what the process looks like inside CE.SDK:
- Compose Visually: The user creates a layout with reference content, uploaded images, icons, color schemes, design elements, placeholder text, and annotations. This composition represents the “prompt” in visual form.
- Add AI Layers: With a single click, the user can trigger image generation using CE.SDK’s built-in AI plugin. The plugin sends the visual context (alongside any optional text input) to a multimodal model capable of interpreting both.
- Refine and Iterate: Users can adjust the layout, reposition elements, change annotations, or layer in new references, then prompt again. Because the canvas is interactive and editable, the feedback loop is tight.
- Build Up Complexity: Over time, users can layer generated images with manually designed components or other generated outputs, creating rich compositions that blend AI creativity with human direction.
This workflow turns the traditional prompt/response cycle into a conversation between the designer and the model, with the canvas acting as the shared language.
Who Is Visual Prompting For?
The use cases for Visual Prompting extend across industries:
- Creative teams can go from reference to generation in seconds, iterating visually instead of wrangling prompts.
- Marketing teams can generate regionalized or personalized creative variants from a shared layout.
- Product designers can prototype in context, turning layouts into realistic screens without leaving the editor.
- Storytellers and content creators can use annotated sketches to generate detailed illustrations or scene variations.
- E-commerce platforms can give sellers the power to visually customize their brand materials with AI assistance.
In every case, Visual Prompting replaces friction with flow and text-based prompting with something more expressive, more reliable, and more fun.
Built for This: Multimodal Models and CE.SDK’s Plugin System
Visual Prompting is only possible because of two parallel advancements:
- Multimodal AI models, such as OpenAI’s
gpt-image-1, that can interpret both images and text, understand spatial relationships, and respond to annotated cues. - A flexible, composable editor SDK like CE.SDK, which enables the construction of visual prompts on a live canvas, and makes it easy to integrate AI models directly into the design flow.
Our SDK was built from the ground up to support AI-first creative workflows. Its plugin architecture allows you to add any model or API, image generation, video generation, captioning, text rewriting and use it natively inside the editor without the need to switch tools or copy/paste.
Generative AI’s full potential is only unlocked when it is embedded directly into the tools creatives use not siloed in chatbots or separate interfaces. Visual Prompting allows that embedding to go even deeper, aligning the mode of input (visual) with the desired output (visual).
Explore It Yourself
🎨 Try out Visual Prompting in our AI Editor demo
📘 Learn How to Integrate AI into CE.SDK
💬 Contact Us to Bring Visual Prompting to Your Product