Deep learning, a subfield of machine learning, has become one of the most known areas in the ongoing AI hype. Having led to many important publications and impressive results, it is applied to dozens of different scenarios and has already yielded interesting results like human-like speech generation, high accuracy object detection, advanced machine translation, super resolution and many more.
There is a steady flow of papers and publications that describe the latest advances in network design, compare existing architectures or describe unseen approaches leading to even better results than the current state-of-the-art. At the same time more and more companies and developers jump on the deep learning bandwagon and deploy the ideas and architectures to real world production systems.
This article describes our approach to applying deep learning to our image editing product, the struggle we had with finding the right architecture and the experiences we made while developing a system that can be deployed to mobile devices.
Our vision
At 9elements, we’ve had various AI topics on our radar for quite some time now. With deep learning, we finally found a tremendous opportunity for our product, the Photoeditor SDK: We believe AI-based algorithms could be the ideal approach to boost our users creative output and simplify complex design tasks.
Given the hype and results, we decided to dip our toes into deep learning, which quickly lead to some research regarding the most common challenges in interactive image editing. We quickly surfaced image segmentation as a major challenge that could be solved using deep learning and started investigating further.
If you have ever tried to select a distinctive region in a picture, say your best friend on the beach or your cute pet, you know the struggle of carefully moving your cursor along the object’s outer bounds until you eventually miss a part or accidentally select something that doesn’t belong to the object. Professional image editing tools can be quite helpful in accomplishing such tasks, but on the one hand, they aren’t available on your mobile device, where you take and publish the images, and on the other hand, can be quite expensive and usually require some hands-on time, before you can produce anything usable.
Our goal was to finally remove the hassle from image clipping. We wanted to reduce the required user interaction to a minimum while offering an intuitive solution that doesn’t require any manuals or online courses. On top of that, as we provide native SDKs for web, iOS, and Android, the solution had to be deployable to all of these systems without relying on a powerful backend or being limited to certain features.
Having formulated our rather ambitious goals, we started our journey by looking into the most common research papers and classic techniques for image segmentation. We then focused on the deep learning part and quickly had an idea on how to design our approach.
Our journey
Image segmentation, the process of classifying each pixel in a picture to be rather fore- or background, is a popular research field and still perceived as quite challenging due to the complicated nature of the task. We, humans, are extremely well trained at perceiving scenes, identifying objects and making logical assumptions based on the visual input we receive.
For a long time, all approaches were based on colors, edges, and contrast and relied heavily on fine-tuned parameters, which had to be adjusted to every new scenario. That changed in 2012 when Krizhevsky et al. presented astonishing object classification results on the ImageNet benchmark using a neural network. Suddenly a system was able to classify objects with unprecedented accuracy and no need for any human fine-tuning. The neural network was ‘just’ trained on the dataset by seeing images combined with their corresponding labels and adjusting its internal representation until it couldn’t learn any further.
As we had already decided on using deep learning for our task, using a neural net clearly was our way to go. We started by examining the existing solutions and approaches, created our first prototype based on our findings and refined our approach and implementation until everything met our expectations.
Scene Labeling
The first approaches we examined focused on segmenting the whole image. This is a common task called scene labeling or semantic labeling, because it allows robots and other systems to understand a scene. The goal is to classify each pixel in an image to a particular object category. An example could be a self-driving car that searches for the road and tries to determine whether any pedestrians are crossing the street. Such a car would try to classify each pixel as road, pedestrian, tree, traffic sign, etc.:

While offering lots of possibilities, the existing solutions were lacking the desired accuracy we needed to provide visually pleasing image segmentations. For a self-driving car, it doesn’t matter if the ‘person’ region for some pedestrian accurately covers the person’s outlines. However, for us it does.
To overcome these issues we experimented with post processing techniques that used the segmentations we found as a base for further optimisations. This lead to our first approach where we would initially segment the entire image using a convolutional neural network, offer the found regions as selectable regions to a user and then try to refine the user’s selection using conventional image segmentations to find the best possible mask.
While already yielding some useful results the system did not quite match our requirements. If the initial segmentation was too coarse or off in critical regions, the user could never select an area that would lead to his desired segmentation.
Image segmentation based on user inputs
We went back to the drawing board and searched for other approaches that would fit our use case. It didn’t take long, and we stumbled upon Deep Interactive Object Selection, a paper that presents an interactive system which creates image segmentations based on user clicks. It looked like a good fit for our requirements, and we updated our existing system to generate fake user inputs and train on combinations of these inputs and images.
To train the net, we used the publicly available COCO dataset, which contains around 300.000 images with more than 2 million annotated object instances. To handle the amount of data, we limited our training data to a subset of the full dataset. This subset was made up of images that contain objects from certain categories and cover a minimum area within the image. As we generated the inputs artificially by adding clicks on the object mask, we could generate as many training data from the COCO subset as we wanted. After some experiments, we settled for three different strategies to create user inputs and trained the net with roughly 300.000 training records.



The masks generated by the updated system were quite impressive already. The neural net could infer which object the user wanted to mask in the image, just by looking at raw pixel data and the user’s clicks on the object. Happy with the first results, we tried to tackle the next hurdle. Before diving deeper into optimizing the neural net, which is a rather error prone process and consumes lots of time, we wanted to deploy the net to a mobile device. We wanted to make sure that such a tool is usable on any device and the performance would match our expectations.
Neural nets on mobile devices
Neural nets are sets of operations, executed in a specific order and based on millions of parameters. Therefore one “run” of such a net requires a lot of computation power, as millions of calculations have to be carried out. At the same time, the millions of parameters need to be deployed, as they represent the model or the representation the neural net has learned during training. So, to deploy our neural net, we had to solve these two requirements on an iPhone.
The first requirement, computing power, was thankfully solved by Apple. With the latest iOS version a specialised framework, called Metal Performance Shaders, was introduced. It offers the all required operations and is tailored to run these on the phones GPU, which is fast and efficient. To execute our net using the framework we had to translate our TensorFlow network code to Swift and rebuild the net’s architecture using Metal Performance Shader operations. Sadly Apple only supports a subset of todays common neural network operations, so we were forced to write some shader code to reconstruct the full network.
The second requirement, extracting the trained parameters and deploying them to the device was much easier. We just had to restore our previously trained model from a TensorFlow checkpoint, write all trained variables into a file and deploy this file with our iOS app. When needed, the iOS app would load the file into memory, and our network implementation would use the given parameters to run an inference pass.
Having met the two requirements, our network worked fine on an iPhone. We added the postprocessing operations and were able to segment images by a single tap without the need for a backend or any network communication. But there were some caveats.
While our neural net was a very common and widely used network, it was huge regarding the trainable variables. A trained model contains ~134 million parameters, which translates to about half a gigabyte of data that needs to be deployed with the app. This was obviously a showstopper for a mobile image editing app, as we couldn’t justify a 500MB download just to be able to segment images with your finger.
Furthermore, the results were still very coarse. If your colleague waved his arms in an image, the net usually could easily detect his torso, head and maybe his legs, but almost never the arms or hands. Fixing this using our postprocessing algorithms wasn’t that much of an option as it would have required lots of computing power and why bother using a neural net with millions of parameters if we fall back to conventional image processing techniques anyway?
So all in all, we had already learned a lot: Our approach of processing user inputs combined with raw image data as neural net input led to usable outputs, although quite coarse. Deploying such a net to mobile devices was possible, and the performance was good enough for using it in an interactive tool. The next step was to optimize the system to fix the parameter size and get finer results.
Combining SqueezeNet and SharpMask
We decided to tackle the network size first, as laying a proper foundation for optimizing the coarseness seemed like a sane thing to do. When looking for small nets with few parameters and fast inference its hard not to stumble across the SqueezeNet architecture by Iandola et al. which was published in November 2016. It met our use case, didn’t use any exotic operations that would be hard to implement on mobile and the results looked promising, so we removed the original network from our system and replaced it with an altered SqueezeNet implementation. And to our surprise, it worked almost right away. We had to tweak our training pipeline, and the results differed slightly, but all in all the small network with only ~5 million parameters matched the performance of our previous behemoth with ~134 million parameters. We quickly updated our conversion script and found out that our deployable model file just shrunk from ~500mb to 2.9mb. What a happy day!

Having solved the network size issue, we went ahead and thought about increasing the precision of our predictions. A loss of resolution is unavoidable in convolutional neural networks, as later layers acquire a larger “view” of the inputs by reducing their input size with so-called “pooling” layers. These layers take for example four values from the previous layer and merge them into a single one. Therefore our new SqueezeNet-based system created a 32 by 32-pixel image mask from a 512 by 512-pixel input image. Up to now we just scaled these up by using a transposed convolution. This allowed the net to learn how the upscaling worked best, but the fine details from the initial input image were already lost at this point.
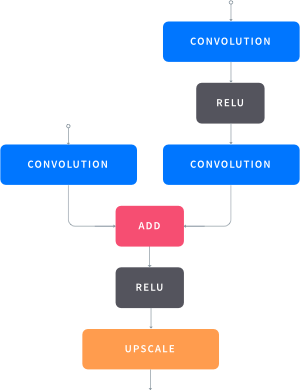
We remembered Facebooks SharpMask system introduced in summer 2016 and revisited the accompanying paper. Their refinement modules seemed like a good fit, as they were able to gradually incorporate features from lower levels, but with higher resolution, into the coarse outputs. We adopted the idea and altered the refinement modules to take the final SqueezeNet output. The modules then combined the coarse SqueezeNet output with the pooling layers intermediate results and were able to refine the result. This increased our model size and the computation costs by a fair amount, but lead to much finer and more detailed results.
Once we settled on our architecture, we started an extensive training run, in which we tested more than one hundred different variations of hyperparameters, architectural details, and resizing techniques. Evaluating the results, we selected a variation, which made the best compromise between accuracy and inference speed/model size.
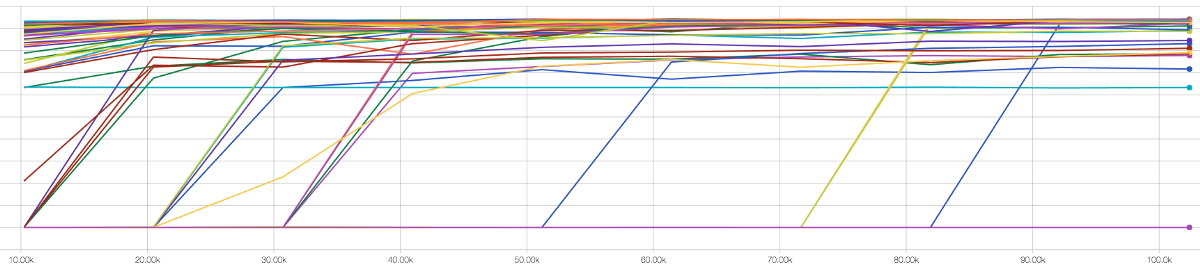
Our results and prototype
Having managed to fix all the issues, we were eager to see how the whole system performed on a mobile device with limited computing power and inputs. We updated our mobile app to use the new network architecture and the freshly trained model to compare the refined system to our previous approach. The results were amazing. When selecting objects that matched the categories of our training data and were fully visible in the image, we were able to generate fine-grained selection masks with just a single tap. More complex or larger objects required a few more taps, but we could always find a selection mask for our object, that was at least a solid starting point for further optimizations.
We decided to build a more polished prototype based on our existing img.ly iOS app. This app uses our PhotoEditor SDK to offer advanced image editing including focus and filter operations. As we were now able to create masks based on objects in the image we quickly settled on enhancing our filter and focus tools with selective masking.
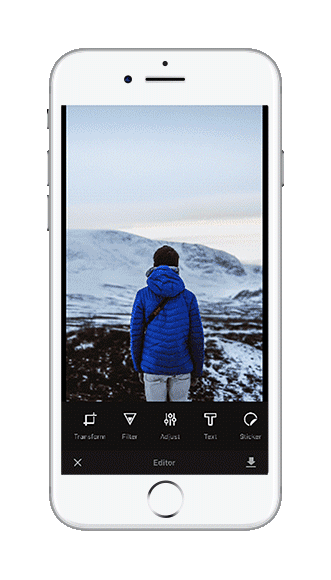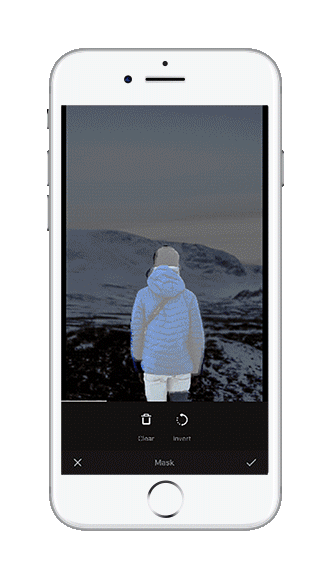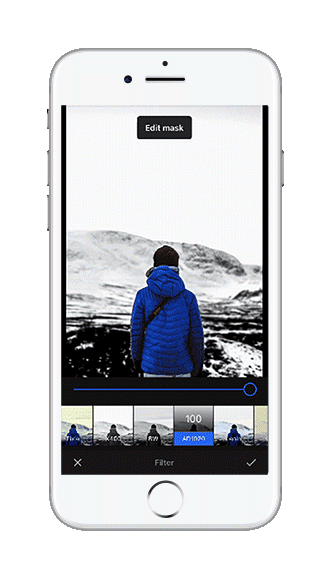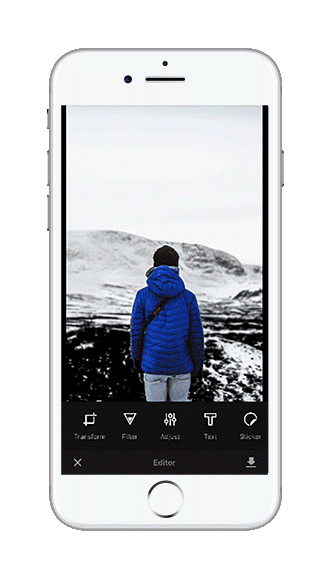
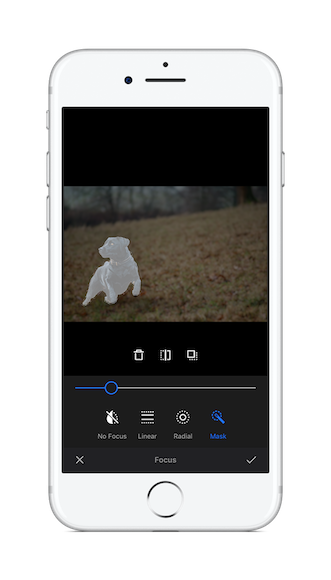
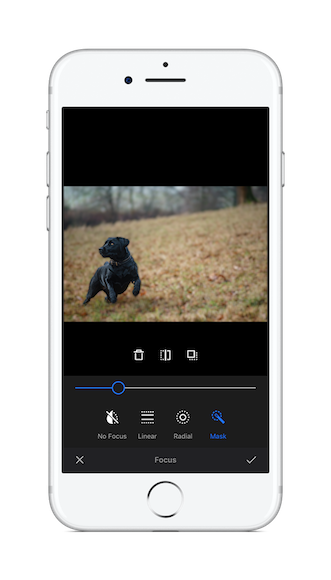
Retrospective
Looking back at our journey into deep learning, it was one of the more frustrating yet fascinating ones. The sheer amount of possible applications is exciting, and once you get the hang of training something on your data, you immediately want to start experimenting with new things. On the other hand, you’re usually building huge black boxes with millions of float values, which makes debugging a pain. Especially when trying to replicate an already implemented architecture on other platforms, this can quickly become rather frustrating. If your outputs don’t match the expected results, your only option is to repeatedly go over your code, check all parameters and hope you stumble upon the wrong number somewhere. But once you manage to set everything up and start seeing some good results, you instantly want to tweak and optimise the bits and pieces of your system.
Overall, deep learning is a pain to debug, but yields great results, opens up a new field of photo editing applications and we’ll definitely keep exploring the new possibilities of applying the techniques in our product. Stay tuned for upcoming features!
Thanks for reading! To stay in the loop, subscribe to our Newsletter.