Navigating the World of AI Models Hosting
Here at IMG.LY, we recently dug into finding the best place to host AI models to support apps we're dreaming up. We wanted to figure out if using cloud GPUs or going serverless would work better for us. As we were looking specifically for service providers to run Image Generation Workloads on, we focused on those that could be the best fit for that. Along the way, we picked up some cool insights and ran into a few hiccups. We think sharing our journey and the things we figured out could help you when you're looking to deploy your own AI models.
First off, we'll explain what cloud GPU and serverless hosting really mean. Then, we'll chat about their good and not-so-good sides when it comes to hosting AI models. It's super important to make sure whatever hosting you choose fits your model like a glove. We'll talk about some tools we stumbled upon that could help with that. Next up, we'll give you a peek at some of the providers we checked out and our thoughts on how they might fit with what we're working on. We decided to skip over the big names like IBM, Google, and Amazon this time. We were curious about what the newer, smaller companies have to offer.
To wrap things up, we'll share some final thoughts on all our research. Plus, we'll throw in some tips and ideas you might want to think about when you're doing your own digging. Whether you're developing AI models or planning to host some of the well-known ones, we hope our adventure helps you nail down the perfect hosting solution for what you need. Ready to jump in?
Kinds of Cloud Hosting for AI Models
Cloud hosting has been around for as long as there has been a cloud. Though the server hardware is not at your location, earlier versions of cloud hosting required that your team learnt lots about server infrastructure. As things have evolved, providers now manage the infrastructure so that you can focus on your work. You can now host even just a single function in the cloud, if that's what you need. In our research, we looked at general serverless hosting and at Cloud GPU AI providers.
Serverless Hosting
Serverless hosting can be defined as an architecture model that lets developers build and run applications and services without managing the servers they run on. The cloud provider manages things like security, provisioning, scaling, and connectivity.
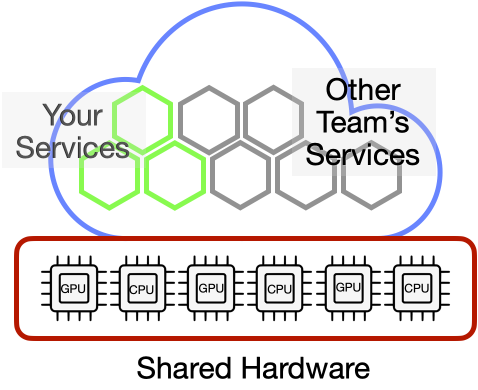
In a serverless CPU-loads hosting the host provisions your services to the most appropriate and available hardware. However, with most of the providers of GPU loads you get to choose.
Serverless Pros:
- Pay-per-compute model: you only pay for the compute time you consume.
- Autoscaling: the provider will automatically scale up or down depending on load, from a few requests a day to thousands per second.
- No server management: eliminates the need for developers to also understand server infrastructure. Often, just a Docker image holding an application is sufficient.
Serverless Cons:
- Cold starts: instance deallocates after a certain idle time (enabling the great pay-per-compute model) so initial request after this can be noticeably slow.
- Limited control over specifics: certain GPU hardware or even server hardware may be unavailable at times which can impact performance.
- Limitations on time - there may be limitations on the execution time of functions, which can impact long-running processes.
Cloud GPU Hosting
Cloud GPU hosting provides access to GPU and TPU (Tensor Processing Unit) hardware that can perform the parallel operations essential for AI model training and inference. The provider allows users to configure specific hardware for their jobs.
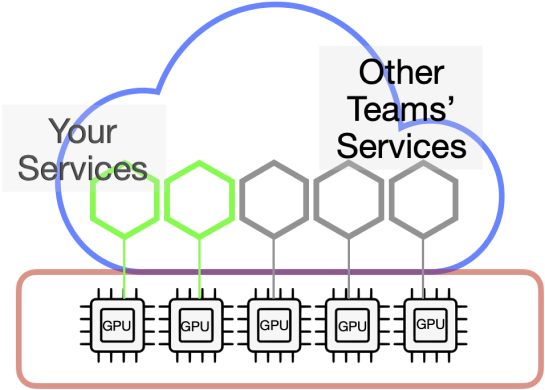
With cloud GPU each service or model gets its own GPU while running. Your other services communicate with the model through an API.
Cloud GPU Pros:
- High performance: GPUs are specifically designed to run AI models and other tasks like deep learning and complex simulations.
- Full control of hardware: users can specify specific hardware configurations for their projects.
- Persistent availability: resources are not deallocated, so there is no latency for provisioning for the first request.
- Cost-effective experiments: the upfront cost of purchasing GPU hardware to experiment with different configurations is eliminated. Services are priced with a pay-as-you-go model.
Cloud GPU Cons:
- Costs over time: costs do not go down during periods of low demand. Over time, costs can potentially surpass the cost of investing in local hardware.
- Management overhead - managing and optimizing hardware configurations is not automatically part of the hosting. You've got to learn some server administration and manage security and upgrades.
Providers
It's important to understand that this isn't a ranking of the best providers or an endorsement. It's what we discovered with some web searching, reviewing the available documentation, and tinkering with any demo or free tools and models the provider makes available. The list could easily have been different providers and we think some of the pros and cons and qualities would be the same. Hopefully, some of the questions we raise and the pros or cons we noticed in our research can help you to guide your research.
Our goal was to find potential hosts for various workflows with different models in a scalable manner. We want to be able to build applications around the workflows. Some of our, specific, requirements include:
- Autoscaling, ideally out-of-the-box without the need for custom Kubernetes setup or similar technologies.
- Minimal vendor lock-in.
- Compatibility with various technologies (REST API, WebSocket, Webhooks, etc.).
- Support for Windows Server.
With those disclaimers and caveats, here is a short summary of our research.
| Provider | Best For |
|---|---|
| Runpod IO (Serverless) | Deploy AI models with GPU support and require customizable API interfaces. |
| Vast AI (Serverless) | Affordable GPU resources and a variety of GPU options for AI model training. |
| Paperspace (Serverless) | Flexible workflows and support for different stages of AI model development. |
| CoreWeave (Serverless) | Strong knowledge of Kubernetes and need autoscaling capabilities for AI workloads. |
| Modal (Serverless) | Comprehensive documentation and examples for deploying AI models in containers. |
| ComfyICU (Serverless) | Serverless infrastructure tailored for hosting ComfyUI applications. |
| Replicate (Serverless) | Easy-to-use API for executing AI tasks without managing infrastructure. |
| Genesis Cloud (Cloud GPU) | Sustainability and need scalable GPU instances for AI model training. |
| Fly IO (Cloud GPU) | To deploy complete applications with GPU support in a scalable environment. |
| Runpod IO (Cloud GPU) | GPU resources in various regions and require customizable Docker-based deployments. |
| Lamda Labs (Cloud GPU) | On-demand GPU resources for model training and inference tasks. |
| Together AI (Cloud GPU) | A platform for testing serverless models and occasional access to GPU clusters. |
If you want to skip ahead to a specific part, here are the providers we will be diving into:
Serverless Providers
Runpod IO (Serverless)
Vast AI
Paperspace
Banana Dev
CoreWeave
Modal
ComfyICU
Replicate
GPU Cloud Providers
Genesis Cloud
Fly IO
Runpod IO (Cloud GPU)
Lamda Labs
Together AI
Serverless Providers
Runpod IO (Serverless)
Concept:
- A Docker image that includes the installation of Python + GPU packages, models, and ComfyUI.
- Python/Go handlers act as an API interface to ComfyUI, which is vendor-specific, but can be wrapped in a more general API for reuse. For more information, see this article on hosting a ComfyUI workflow via API.
Pros:
- Good documentation, including public GitHub repositories with examples.
- Relatively large community for a new provider.
- Compatibility with Windows Server.
- Handlers allow for webhook and WebSocket-like communication for API feedback.
- Network volume to store models/data and reduce cold start times.
- Control over the number of workers and the ability to define persistently active workers.
Cons:
- Availability of GPUs, especially in Europe, needs to be validated.
- Handlers can only be written in Python and Go.
Open Questions:
- General open questions regarding serverless infrastructure and AI inference tasks.
Conclusion:
The overall package seems very mature. The setup can largely be adopted from the GitHub examples. Good documentation and community support (notably on Reddit). The open questions regarding pricing and cold starts are typical for serverless infrastructure.
Vast AI
Concept:
- Peer-to-Peer Sharing. Companies/organizations can rent out their unused GPUs.
- A GPU Marketplace approach.
Pros:
- Affordable prices through their peer-to-peer GPU sharing model.
- A wide selection of different GPUs.
- Good global availability of GPUs.
- Ability to define autoscaler groups, allowing different workflows to scale differently.
Cons:
- The autoscaler is currently only in beta mode.
- Data privacy/security concerns when renting GPUs from anonymous providers.
Open Questions:
- How will the autoscaler beta evolve?
- Control over GPU providers: Can one allow only certain trusted providers (e.g., those based in the EU)?
Conclusion:
Even though the pricing is more affordable, there may be significant issues, in terms of security and data protection, as well as the fact that the autoscaler is still in the beta phase.
Paperspace
Concept:
- The serverless approach (Workflows or Gradient) is still in beta Paperspace Gradient Workflows is based on Argo Workflows which utilizes Kubernetes.
- A predefined API is available for communicating with workflows, as detailed in DigitalOcean's documentation for Paperspace commands.
Pros:
- The ability to use different machines (GPUs) at different stages of a workflow.
- Provided by Digital Ocean, allows for general hosting customers to expand into GPU hosting without finding a new vendor.
- Possible Windows support as outlined in DigitalOcean's documentation on running Windows apps.
Cons:
- Complex documentation: offers many features for various use cases (AI learning, data preparation, validation, and inference).
- Vendor lock-in through a proprietary system: Gradient Workflows and YAML config are specific to Paperspace.
- No real-time feedback over the API.
Open Questions:
- Since it's still in beta, how will the ecosystem continue to develop?
- How extensive is the knowledge of Kubernetes required to implement autoscaling?
Conclusion:
It's positive that it's offered by Digital Ocean as they are a more mature company with general hosting experience. The approach seems very specific to Digital Ocean. Furthermore, it may require experience with Kubernetes.
Banana Dev
It has been excluded: Recently, they announced the termination of their serverless model as it was not cost-effective.
- Learning from this: Currently, there are many new providers entering the market aiming to establish themselves as cloud GPU or serverless GPU providers. This highlights the importance of minimizing vendor lock-in.
CoreWeave
Concept:
- Heavily based on Kubernetes.
- A Kubernetes file is created for setup; scaling and additional infrastructure are managed by Core Weave.
Pros:
- Autoscaling by default with the possibility of scaling to zero.
- Supports Windows.
- Minimal vendor lock-in due to Kubernetes configuration.
Cons:
- Strong dependency on Kubernetes, with the serverless setup based on KNative documentation.
- Does not offer a handler API, etc., to communicate directly with ComfyUI.
Open Questions:
- How complicated would it be to implement an API interface and resulting scaling to address the correct instances, etc.
Conclusion:
Good documentation and a close interface to Kubernetes. For a team with strong knowledge of Kubernetes, this could be a prime candidate.
Modal
Concept:
- Container Setup: Containers are defined through Modal's own container setup Modal custom container documentation.
- Docker images can also be used.
- Modal-specific handlers to communicate with ComfyUI and other models.
Pros:
- Supports webhooks and custom endpoints Modal webhooks documentation.
- Focus on fast startups/cold starts.
- Emphasis on AI inference tasks.
- Comprehensive documentation with many examples.
Cons:
- Vendor lock-in if Modal's container setup is used.
- Autoscaling and scaling configuration are not directly described.
Open Questions:
- How exactly does the autoscaling work?
Assessment:
For us, this is a candidate for closer consideration. The container setup can be managed through Dockerfiles, and the API defined by Modal's own interface.
ComfyICU
Concept:
- Pure focus on ComfyUI, serverless infrastructure.
- API interface for communication.
Pros:
- Minimal setup effort.
Cons:
- Limited control over the API.
- Limited GPU resources.
Open Questions:
- How does the autoscaling work, if it exists at all?
- Community-based open source. What is the long-term support for this project?
Conclusion:
Potentially useful for testing or building a demo site, but probably not suitable for developing our commercial applications.
Replicate
Concept:
- Execution of AI tasks/models in the cloud via an API.
- No access to infrastructure, etc.
Pros:
- Supports various languages: Node, Python, Swift.
Cons:
- No control over the infrastructure, number of GPUs, or workers.
- API rate limits.
Open Questions:
- How can autoscaling be enabled?
- Is it possible to create custom API endpoints, webhooks, websockets?
Conclusion:
For testing or as a demo for one's own model, this can be a very good platform. However, as a standalone application interface, it doesn't meet some of our core requirements.
GPU Cloud Providers
Genesis Cloud
Concept:
- Focus on sustainability and renewable energy.
- Scaling through instances as detailed in here.
Pros:
- A REST API is available for managing instances.
Cons:
- The availability of GPUs varies significantly by region.
- Limited selection of GPUs.
Open Questions:
- How quickly can new instances be scaled up or down?
Conclusion:
The use case for Genesis Cloud appears to be more suited for model training or tasks that require a significant amount of computing power for extended periods.
Fly IO
Concept:
- Focus on the deployment of complete applications.
- Also offers its own GPU servers.
Pros:
- Docker File support with additional configuration via a TOML file.
- Quick scaling of GPUs up or down facilitated by the launch process.
Cons:
- Limited selection of GPUs, with only very large GPUs available.
- Specifically tailored for Linux.
Open Questions:
- How well does the launch system perform for relatively fast inference tasks?
Conclusion:
Since primarily large GPUs are available, the focus here also appears to be more on model training or other long-duration tasks. However, the launch system might also potentially be used for inference.
Runpod IO (Cloud GPU)
Concept:
- A wide range of GPUs available across various regions.
- Base Docker images for popular tasks or support for custom Docker images.
Pros:
- Many different data center regions.
- A variety of CPUs available.
- Simple setup via Docker images.
Cons:
- No direct autoscaling (would need to use Runpod Serverless for that).
- Despite a large selection of GPUs and many different data center locations, the availability of GPUs is not very high.
Open Questions:
- Can autoscaling be implemented without using serverless?
Conclusion:
The setup can largely be adopted from the GitHub examples. There is good documentation and a community (much of it on Reddit). The availability of GPUs could become a problem, especially for smaller GPUs.
Lamda Labs
Concept:
- On-demand cloud with a focus on model training and inference.
- Similar concept to Runpod, offering a variety of GPUs.
- GPU availability is very limited.
Conclusion:
Runpod and Lambda Labs seem to have a similar approach and similar offerings. Runpod appears to have greater availability.
Together AI
Concept:
- Offers an API and playground for testing serverless models.
- Also offers GPU clusters but only upon request.
Conclusion:
We didn't dig into the GPU clusters since information is available only upon request. Otherwise, in the API/serverless area, it appears to be similar to Replicate.
Established Providers
As we said in the introduction we did not examine the old, large providers like Google Cloud, AWS, Azure, Nvidia, etc., in detail. Rather, we focused on the new providers aiming specifically at the market segment of AI GPUs. With the older providers, we are more in the realm of cloud GPUs and less in serverless. Given the size of these providers and the wide range of market segments they cover, it can make sense to opt for them if one is already familiar with their architecture and documentation.
- Google Cloud Platform (GCP)
- AWS
- Microsoft Azure
- IBM Cloud
- NVIDIA GPU Cloud (NGC)
Conclusion
Just as we saw that performance can vary wildly for different models, pricing can be similarly complex. When evaluating costs, consider factors like response times, the number of required workers, and potential charges for features like caching. Many providers offer detailed pricing guidelines on their websites, which can be crucial for ensuring you only pay for the computing power you truly need. Experimenting with performance of your model and applications during development will be helpful to make sure your hardware and pricing are both optimized for your application.
Another thing to consider is what kind of experience does your team already have? Most cloud GPU services provide tools like CLI or REST APIs to manage resources, which can be a steep learning curve if your team is not familiar with these technologies. Additionally, while serverless platforms may support multiple programming languages, compatibility with your team’s preferred language—be it JavaScript, Python, or Go—is essential. As exciting as it can be to learn new languages, it's probably not the best use of your team's time.
The size of files you'll be moving between your model and the other parts of your project may also be a factor. Your users may not notice latency for models that communicate using text only. Text moves quickly from point to point in a network. However, if your model takes large image files as input or output, you may find that moving data between data centers is too slow. Then you'd want to focus on providers who can offer more general hosting in addition to cloud GPU hosting.
As we continue to research this for our own projects, we are thinking the best configuration for us is to use a cloud GPU exclusively for generation tasks and communicate with it via an API from our existing back end. We will have to experiment to see if we can have those functions geographically separate, or if we need to find one hosting company and one data center for both. As we learn more we may change our ideas, but that's part of the fun of working in technology, things change. By using the higher-cost cloud GPU for as few tasks as possible, we'll know we aren't wasting compute power for things easily handled by a general CPU.
We hope this has given you some useful background and ideas as you research hosting options for your AI projects. Understanding the subtle differences between serverless and cloud GPU hosting can spark innovative ideas tailored to your needs. Perhaps some of the lesser-known providers we've explored might just be the perfect fit for your next project. As always, the dynamic nature of technology keeps us on our toes—ready to adapt and evolve. Happy hosting!
Thanks for reading. Join over 3000 specialists with powerful apps and subscribe to our newsletter. We keep you in the loop with brand-new features, early access, and updates.