



Pictures are omnipresent on the social web. It is common to instantly post photos of all kinds of events to share with friends and followers. Also, businesses want to show presence on social networks and employ designated social media managers to represent the company and to communicate to customers.
Let’s assume you work as a social media manager in a company. Your job is to communicate with customers and represent your company on various social media platforms. One part of your job is to share pictures of your company’s work. Since you’re serving multiple social media platforms, you always have to consider their specific aspect ratio requirements for images. One platform wants you to provide square photos, whereas another one asks for pictures in a wide landscape format.
You are a busy person, you don’t want to waste time on cropping hundreds of images into the proper format, but you also don’t want to crop your pictures weirdly.
Suppose you want a portrait-oriented version of the following image. Simply choosing the center would lead to an odd picture containing only one half of the bird. What you want is the image to include the region of interest; here, probably the whole bird in the center of the image.
But how can we automatically find such image regions?

When humans look at images, they intuitively focus on significant elements of the photos first. If you look at the following pictures, …


… you will probably notice that your first focus on the salient parts of the image (maybe the geyser or the sundown for the first image, and the reindeers on the road for the second image).
As it turns out, it is possible to train neural networks to predict such salient regions. A prediction of such a network is called a saliency map. It basically is a grayscale image of the same size as the picture. Each pixel intensity encodes the degree of saliency. These saliency maps allow us to find the best image region for a given aspect ratio.
But how can networks be trained to predict salient regions in a picture? And how do we, given the salience information, crop an image to an optimal region?
Fortunately, there was already a considerable amount of research regarding saliency prediction. Basically, there are two main approaches: attention-based saliency prediction and segmentation based saliency prediction. The first group focuses on predicting the center points of human attention regardless of object segmentation and boundaries, whereas the latter considers the most salient objects as a whole.
For our application, it seemed more suitable to choose an attention-based approach. We decided to go with an LSTM based model.
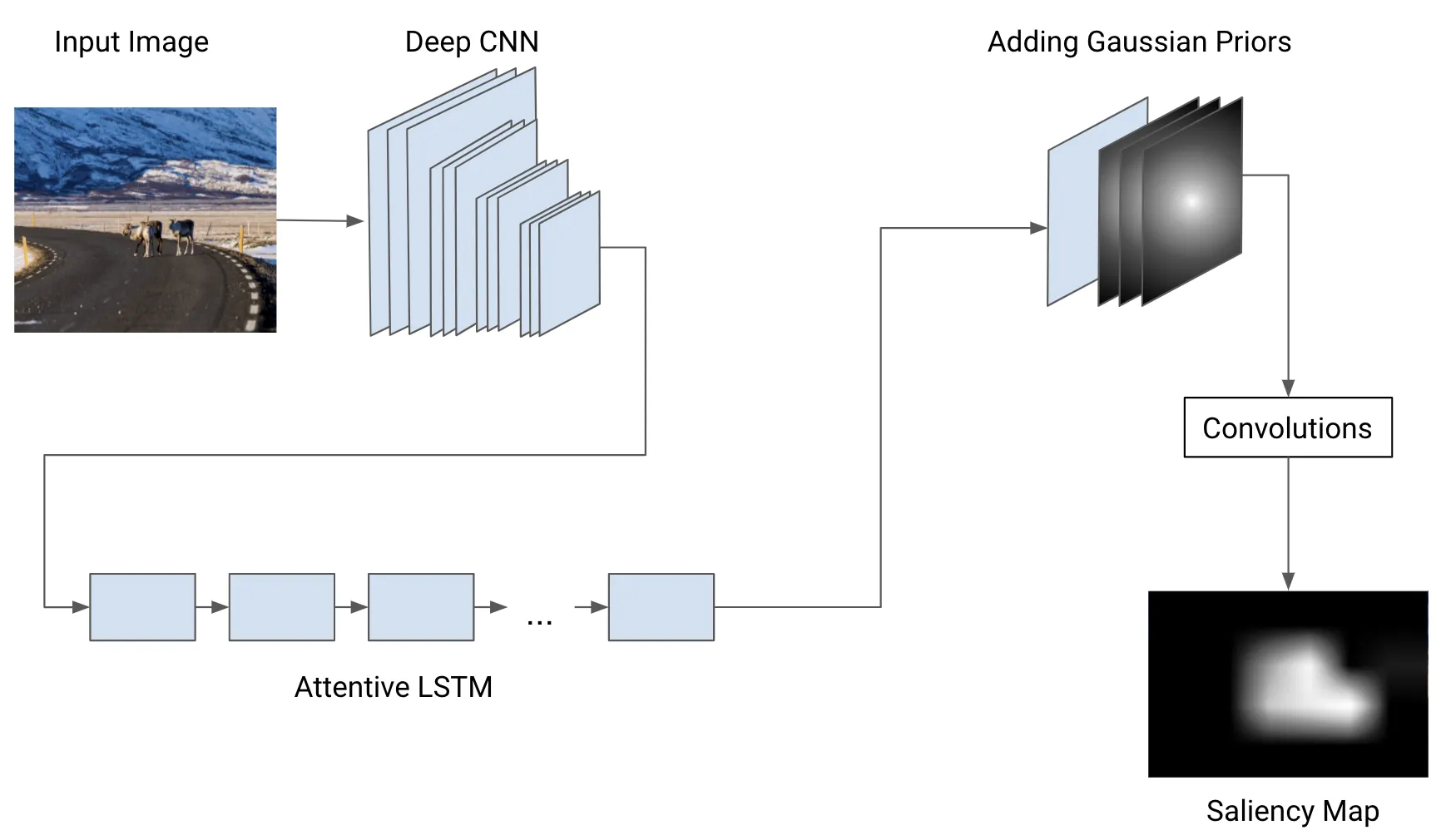
Briefly summarized, the approach works as follows: A deep convolutional neural network (CNN), pre-trained on image classification, acts as a feature extractor. The value of some intermediate layer (or hidden layer) is forwarded to the recurrent LSTM that further improves the prediction. The saliency map then is the output of the LSTM, combined with the Gaussian priors.
In particular, a dilated convolutional network, in our case, a modified RESNET50 already pre-trained on the SALICON dataset, is deployed for feature extraction. The original paper for this method used a network for image classification. Many CNNs can act as feature detectors, but they don’t perform equally well. For example, compared to the standard convolutional feature extraction networks, the dilated networks prevent the harmful effects of image rescaling on the saliency prediction. The extracted feature maps are then fed into an attentive convolutional LSTM (recurrent neural network). This iteratively improves the saliency prediction on the obtained feature maps. Finally, multiple trainable (isotropic) Gaussian priors are added to take the bias of human attention into account, since humans tend to focus on the image center.
We trained the network on the SALICON dataset, which includes 20,000 images from Microsoft COCO and 15,000 corresponding saliency maps. The saliency maps were generated by empirical studies modeling human eye fixation by mouse movements. We optimized our network with a composed loss function considering the Pearson Correlation Coefficient and the Kullback-Leibler divergence, representing standard saliency prediction loss measures.

With this approach, we could already predict pleasing saliency maps suitable for smart image cropping. Unfortunately, our first successful model took up way too much memory, thus being useless for practical applications. Therefore we had to compress the model to a suitable size while maintaining the smart cropping performance as high as possible. After a while of unsatisfactory trials, we found that instead of the RESNET50, we could just deploy the way smaller Keras-intern MobileNet as our feature extraction model.

This model option indeed provides less precise results for the saliency map prediction. However, it is still suitable for the smart image cropping, since we only need to know the position of the focus points roughly. Not only could we save much memory capacity employing this model variation, but also we could increase the runtime of our model significantly, which was our goal. This way, we created a model suitable for practical applications that are supposed to take over the inconvenient manual cropping process.
Once we have the saliency map, the smart crop can be determined quite easily. First, we compute the edge length of a window covering the given image as much as possible while fulfilling the required aspect ratio. Afterward, we slide this window over the predicted saliency map and determine the position that maximizes the covered saliency density. Now we only need to crop the image based on the optimal window position. Thus we obtain our smart cropped image suiting the required aspect ratio. The method is inspired by this paper.

To sum up, using saliency prediction and maximization, smart cropping enables us to find the best image regions for any aspect ratio. This technique, which we’re currently building into our UBQ engine, reduces the user’s burden to manually crop images into the required aspect ratio.

This project was funded by the European Regional Development Fund (ERDF).


