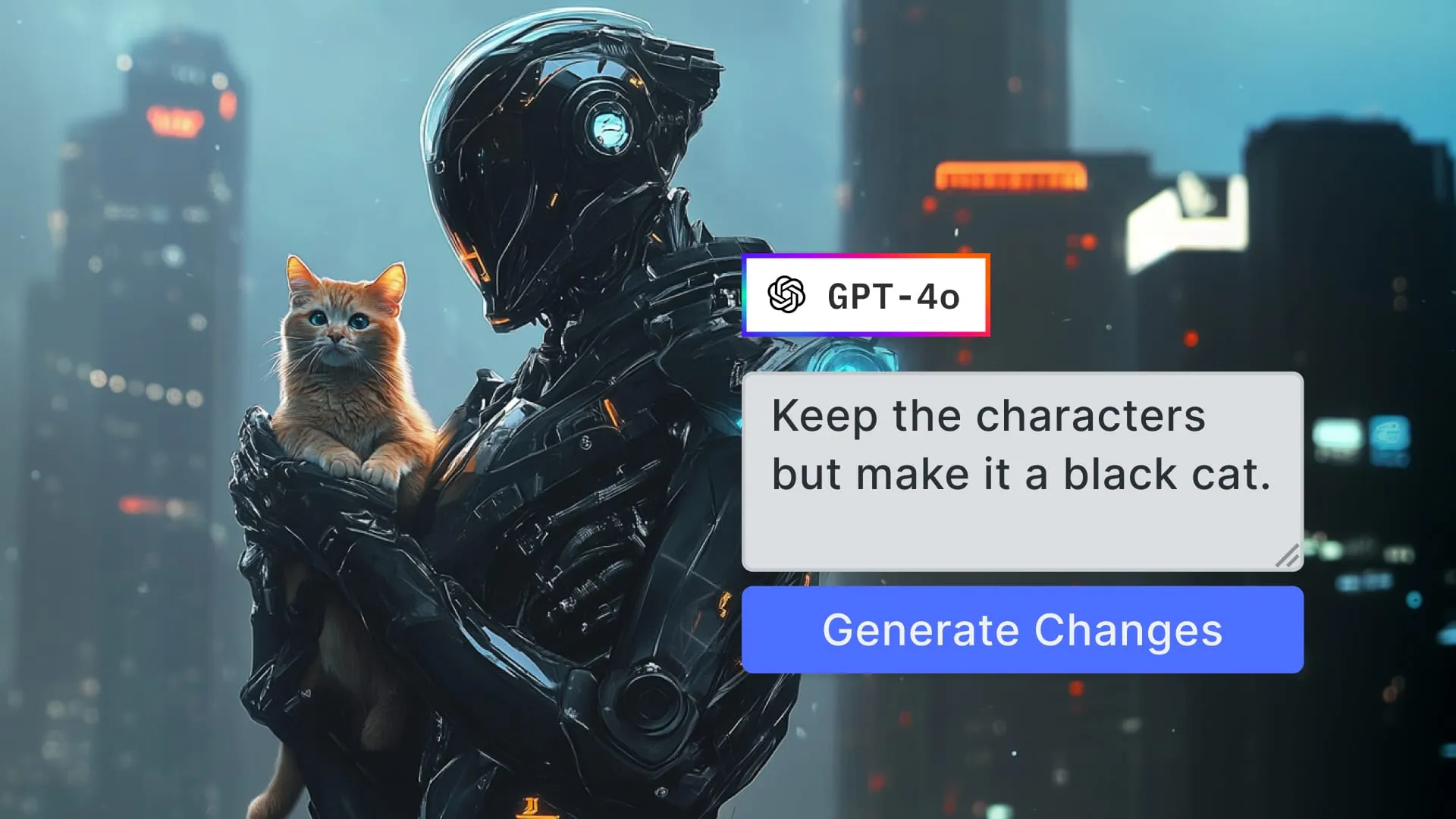
If you’ve been working with image-generation APIs over the past year, you’ve probably gotten used to a certain flow: send a prompt, wait a few seconds, and get a flat image back. It’s a one-shot deal. Useful? Definitely. But not exactly interactive. That’s what will change with OpenAI’s upcoming GPT-4o image-generation capabilities.
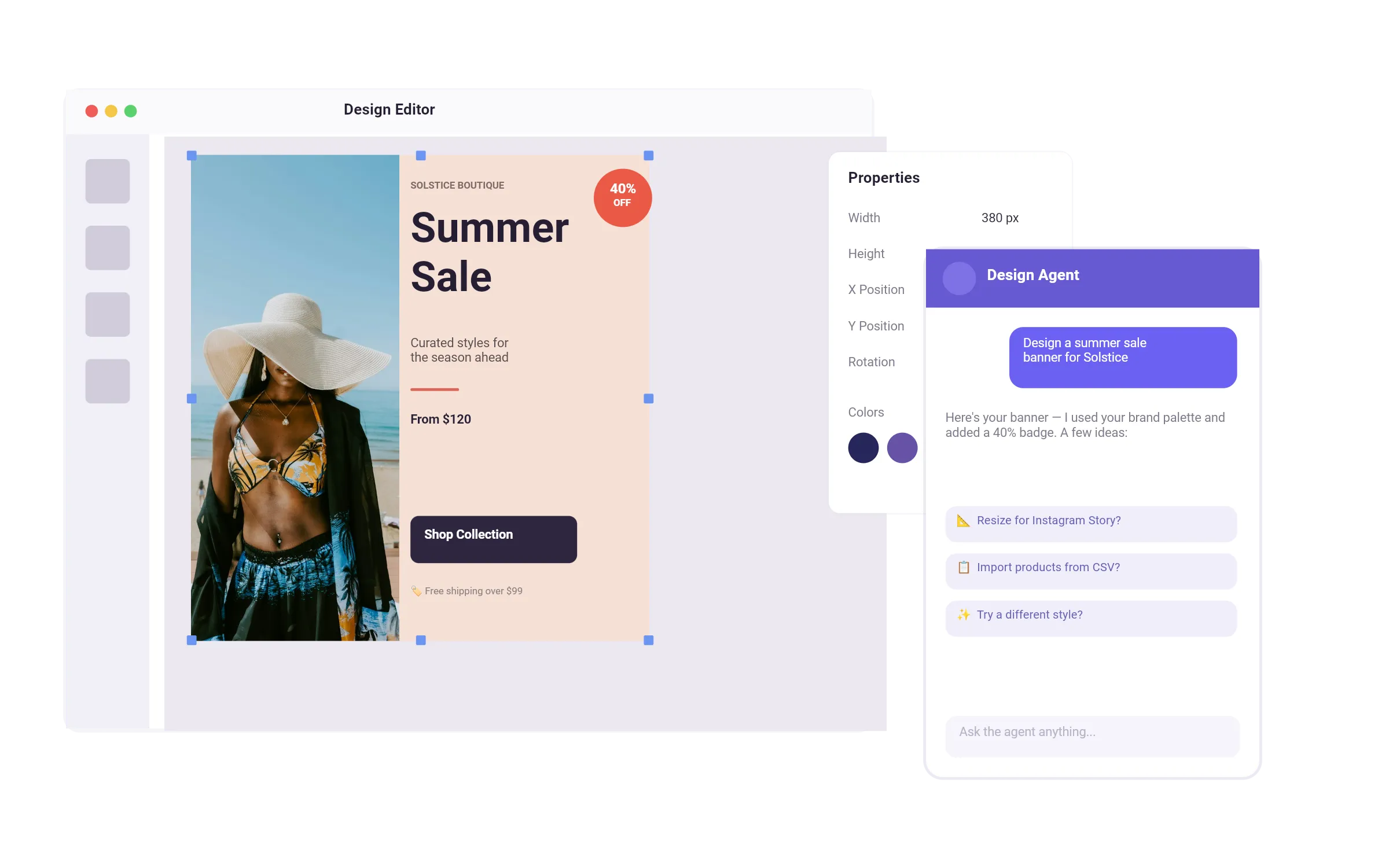
IMG.LY, which recently released a suite of AI features for its design editor, is eagerly awaiting the release to expand how users can interact with AI-driven creativity even further.
Update: AI-first Visual Editing
A day after the release of the gpt-image-1 API, we put the UX principles outlined in this post into practice and integrated it into CreativeEditor SDK. Users can now generate images, create variants and use the canvas to compose visual prompts with our design editor. See it in action:
GPT-4o: Beyond the Prompt-to-Image Pipeline
GPT-4o isn’t just another version of DALL·E. It represents a shift in how developers will integrate AI into creative applications. While DALL·E 3 is powerful it is also somewhat siloed (you send a prompt, you get an image), GPT-4o looks like it will be part of a much more dynamic, conversational model one that accepts both text and image inputs, and could soon generate visual content in context, on the fly, and as part of a back-and-forth user interaction.
If you’ve used ChatGPT recently, you’ve already seen glimpses of this. You can drop an image into the chat, ask GPT to describe or edit it, and get a response that feels fluid and visual. Developers should expect the API version to follow a similar pattern. It likely won’t just be a /generate-image endpoint. Instead, we may be looking at an extension of the chat/completions endpoint that handles multimodal messages. That changes the way you integrate this capability into your application. Rather than simply placing an image generation step in your pipeline, you will have to build your app’s UX around this new user flow. This comes with its own set of unique challenges.
Rethinking the Interface: Prompting as a Conversation
So what does this mean if you’re planning to integrate multi-modal image generation into your own product? For starters, you’ll probably need to rethink how users initiate and refine prompts. In the DALL·E flow, you might offer a text box with a few style dropdowns and call it a day. But in a GPT-4o world, your UI needs to support image inputs, persistent context, and dynamic editing, image gen becomes more like a conversation than a command.
This is where the rubber meets the road. The tools that will benefit most from GPT-4o aren’t static generators but interactive editors. Think collaborative design apps, video editors with generative overlays, or product customizers that let users sketch or upload a photo and then iterate with AI. Put differently, the model output isn’t the endpoint but rather a checkpoint in the creation process.
A Typical Iteration Cycle in a Multimodal Workflow
Here’s a rough sketch of a workflow we might be seeing more of: The user starts with a prompt and an image, maybe a rough sketch or collage created inside an editor, a product photo, or a UI frame. GPT-4o returns a generated image based on that input. The user then edits or annotates the result, maybe adds new prompt text for refinement, and resubmits that combination to further develop the output. This cycle might loop several times: generate, tweak, refine, regenerate.
That’s a fundamentally different interaction model from past AI tooling. It’s less about one-off generation and more about a guided creative journey, where the user is in dialogue with the model. The result: better alignment with the original intent, more control, and more usable creative outputs.
There is an additional, more subjective benefit to this kind of workflow: it gives the user a sense of autonomy again; they are back in the driver’s seat and less at the whim of an inscrutable machine. In many contexts, that makes a difference. Most notably, as we discussed in our white paper on print personalization, the psychological benefit of personalization lies to a large extent in the investment, the sense of ownership that comes about when you create something. “Make it yours” is the common tagline attached to personalization campaigns in e-commerce. That only works if the user exerts more control over the output than iterating over a set of prompts.
The most pithy encapsulation of this paradigm that I have heard is Humans on top, AI on tap.
Persistent Elements and Visual Consistency
One particularly interesting frontier here is character and object persistence. If a user defines a character early in the workflow, either via prompt, image, or a combination, they’ll increasingly expect that character to appear consistently across assets. Think of it as visual continuity, whether you’re generating scenes in a story, slides in a deck, or frames in a video.
If the user of a creative marketing cloud creates a campaign avatar or mascot, that character needs to be consistent within and across campaigns.
Being able to reference earlier outputs, prompts, or style cues gives the user control over not just individual assets but the whole arc of the design narrative. GPT-4o’s ability to maintain that continuity is a game-changer for workflows that involve storytelling, brand identity, or serialized design work.
What to Expect from the API
Technically, if GPT-4o follows OpenAI’s recent design philosophy, you can expect a JSON-based API with a messages array, where content can include both text and image_url types. The output will likely be returned either as an image URL hosted by OpenAI or as base64-encoded image data, depending on the format you request.
That structure plays nicely with modern JavaScript front-end frameworks. React, Svelte, and Vue are all well-suited to async generation flows with visual previews. If you’re already using tools like Zustand or Jotai for local state or something like tRPC or GraphQL for structured calls, you’re in a good position to layer GPT-4o in without breaking the flow.
Trade-offs and Technical Considerations
There are trade-offs, of course. GPT-4o will probably cost more per call than a standard DALL·E 2 or 3 generation. Its latency is still an open question, and the multimodal input support will likely require more thoughtful UX decisions. What happens when a user drops an image and wants to undo just part of the generation? Where do you store prompt context for edits? How do you communicate what’s editable and what’s not?
This is where design and engineering need to work together. You’ll want to build an interface that makes AI feel like a creative partner, not just a backend service. That might mean giving users a visual prompt history or allowing partial re-generations of specific canvas elements. You’ll need sensible fallback states. What happens when generation fails or the result isn’t what the user wanted?
Where IMG.LY’s CE.SDK Fits In
We have already given the questions raised above some serious thought, and most of the complexities introduced by this new workflow are the table stakes for the Creative Editor. So, if you’ve already integrated IMG.LY’s CE.SDK, we have taken care of most of these problems, and you can seamlessly integrate with any AI model. We are actively working on an off-the-shelf integration of the GPT-4o image model once its public API launches.
In general, you can treat GPT-4o’s image outputs as just another layer in the editing canvas, positioned, styled, cropped, and ultimately editable in the same environment as everything else. That’s the real power of multimodal workflows: not just generating but integrating. And once GPT-4o’s API goes live, you’ll want your infrastructure ready to slot it in with minimal friction.
The Loop: Prompt, Generate, Refine
The era of single-shot generation is winding down. What’s coming next is a loop: edit, prompt, generate, refine, repeat. And this loop doesn’t just belong in the backend, it needs to live in the UI, in a way that invites user input, creativity, and correction.
We’ll be publishing more on how this integrates into IMG.LY’s upcoming AI workflows soon. Expect tools that don’t just generate visuals but help teams and individuals work through ideas in real time. Because especially as AI gets more potent, it needs humans on top.
3,000+ creative professionals gain early access to new features and updates—don’t miss out, and subscribe to our newsletter.