What We Built
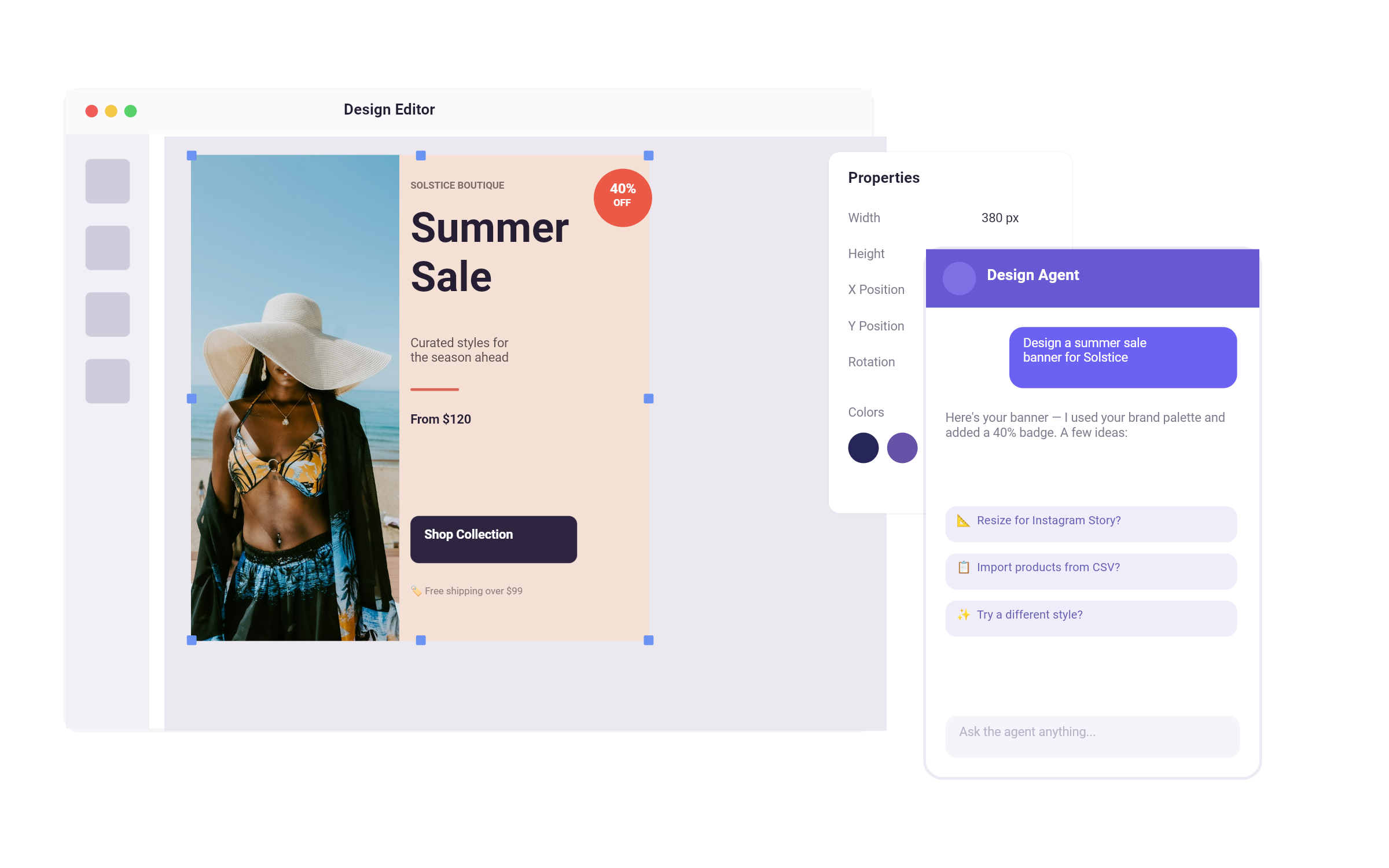
We integrated OpenAI’s new gpt-image-1 API (from GPT-4o) directly into our fully functional visual editor, CreativeEditor SDK (CE.SDK), enabling generation, editing, and refinement of images without ever leaving your creative workflow.
From Simple Image Generation to Visual Prompting on a Canvas
Inside the editor, users can now:
Generate Images
Use prompts to generate images from scratch.
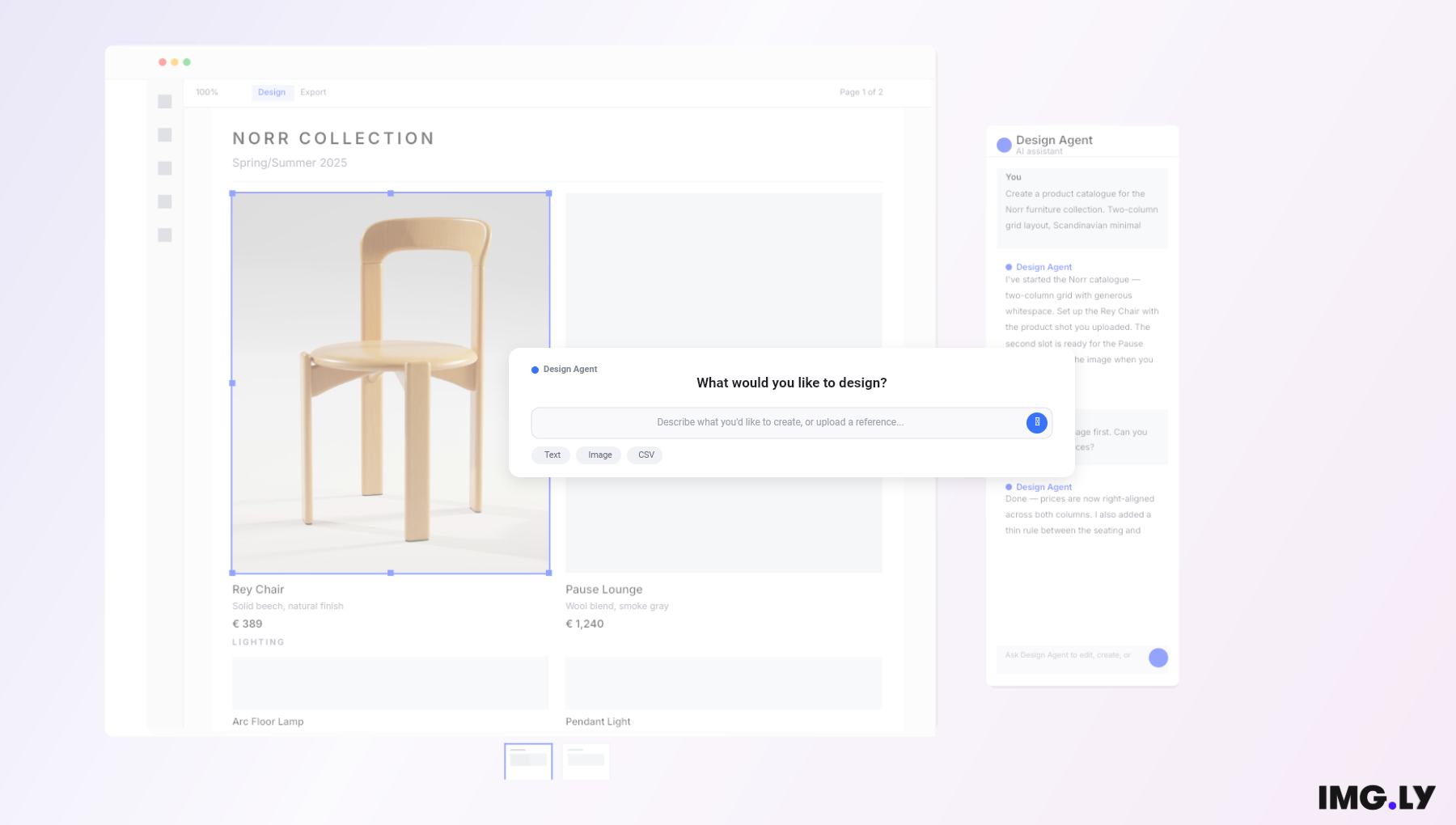
Generate Images from Visual Prompts
Turn full compositions—images, text, and annotations—into fresh visual content. Just select your page and let AI handle the rest, as shown in the video.
Reimagine Images & Text
Edit existing images and text with prompts to iterate faster and create variants.
Create Incredible Compositions
Combine generated and uploaded images into complex compositions.
Each step builds on the last, evolving from basic generation into true visual prompting powered by multiple input modes, all within one canvas. Check out the live demo here.
How We Built It
We built this integration using our CE.SDK and its flexible plugin system, designed from the ground up to support AI-first creative workflows.
This approach lets developers plug in any model or API—text, image, video, or audio—and run them all in one seamless editing flow. Whether you're using OpenAI, Stability, or an in-house model, CE.SDK gives you the tools to bring it into the visual workflow natively.
🔗 Check out our AI Editor.
📘 Learn how to integrate AI into CE.SDK.
Why This Matters
Generative AI’s full potential isn’t unlocked by prompting alone, it’s unlocked when embedded into real-world creative workflows.
Designers, marketers, and content teams don’t just need outputs; they need control, iteration, and context. By bringing AI directly into the canvas where assets are created and edited, we turn generative models into tools for actual production, not just ideation.
This shift enables:
- Creative work in context: No switching between ChatGPT and design tools.
- Real-time augmentation: Prompt, edit, refine in place.
- Scalable content generation: Automate localization, personalization, and variants.
- Multimodal orchestration: Use visuals, layouts, and annotations as inputs.
It’s a step toward making multimodal AI usable for real design workflows, not just concept generation.
Integration & Feedback
This linked demo is rate-limited, if you would like to test more extensively or if you are interested in giving the AI editor a spin inside your own app, you can get started with our documentation.
We’d love your feedback, any thoughts, questions, and ideas are welcome!
Reach out to us.
3,000+ creative professionals gain early access to new features and updates—don't miss out, and subscribe to our newsletter.